-
トラブルシューティング ガイド
グラフ、レポート、データソースで問題が発生した場合は、このガイドにその問題が記載されているかどうかを確認し、記載されている場合は [Steps to resolve](解決方法)をクリックして、問題を詳細に調査および修正する方法をご覧ください。
この記事の内容:健全性維持の基本手順
Looker Studio に関する問題の中には、一時的なネットワーク エラーやバックエンドの誤動作が原因で発生するものがあります。問題のトラブルシューティングに多くの時間を費やす前に、以下の健全性維持の基本手順を実施することをおすすめします。1 つの手順を試すたびに、問題が解決したかどうか確認してください。
発生する可能性がある
エラーや現象- ページが応答しない
システムエラーLooker Studio が利用できない
解決手順
- ブラウザ ウィンドウを更新します。
- ブラウザ キャッシュと Cookie をクリアします。
- ブラウザを再起動します。
- 別のブラウザを使用してみます。
- パソコンを再起動します。
- 可能であれば、別のパソコンを使用してみます。
上記の手順を試しても問題を解決できない場合は、少し待ってから再度確認します。問題が解決しない場合は、同じ問題が発生しているユーザーが他にいないかどうかを Looker Studio コミュニティ フォーラムで検索して、ご確認ください。
アクセス権限に関する問題
Google Workspace または Cloud Identity をご利用の場合、Looker Studio を使用するには、組織の管理者が Looker Studio を有効にする必要があります。
発生する可能性がある
エラーや現象このサービスへのアクセス権がありません。組織の管理者にアクセス権の付与を依頼してください。解決手順
組織の Looker Studio を有効にするよう組織の管理者に依頼します。詳しくは、Looker Studio のエンタープライズ機能に関する記事をご覧ください。接続に関する問題
データ接続に関する問題が発生する原因は複数あります。共有されているデータソース内のデータを表示するための適切な認証情報がない場合などには、なんらかの問題が発生することが想定されます。その他の理由としては、設定が破損しているまたは未完了であることや、データソースが削除されていること、データに対する認証の喪失などが挙げられます。
データセットへの接続に関する問題を解決するには、以下の手順をお試しください。
発生する可能性がある
エラーや現象データソースがありませんデータセットの設定エラーデータセットにアクセスできませんデータソースが接続されていませんデータソースを追加する必要があります基盤となるデータが変更されましたデータベース接続エラー
解決手順
- 破損したコンポーネントを編集してから、正しいデータソースを追加します。
- データソース フィールドを更新します。
- データソースを再接続します。
- レポートからデータソースを一旦削除し、再度追加します。
- 新しいデータソースを作成して、動作するかどうかを確認します。
- Google アカウントへの Looker Studio のアクセス権を取り消し、復元します。
グラフの設定に関する問題
不完全または互換性がないグラフの設定がグラフに含まれている場合、エラーが表示されます。
発生する可能性がある
エラーや現象システムエラーグラフの設定が未完了です指標とディメンションの組み合わせが無効です
解決手順
- 無効な計算フィールドを修正または削除します。
- グラフの各種フィールドを選択します。
- データソース フィールドを更新します。
- データソースを再接続します。
「指標とディメンションの組み合わせが無効です」のエラーについて
このエラーは、データソースでサポートされていない方法でグラフでデータを可視化しようとした場合に発生します。これは、特定のフィールドのみ同時にクエリできる固定構造にデータが保存される Google アナリティクスや Google 広告などの一部のバックエンド システムの制限事項です。
ヒント: Google アナリティクスのデータについては、ディメンションと指標のリファレンスを使って互換性のあるフィールドを見つけることができます。ユーザー インターフェースや機能に関する問題
Looker Studio が突然動作しなくなったり、誤作動したりする場合は、互換性のない拡張機能やアドオンが原因であることが考えられます。
発生する可能性がある
エラーや現象- 機能が動作しない
- UI 要素が表示されない
- サービスが応答しなくなった
解決手順
- 上記の健全性維持の基本手順を試してみます。
- 他のブラウザを試してみます。
- ブラウザの拡張機能やアドオンを無効にします。
すべての拡張機能を無効にして問題が解決した場合は、問題の原因となっている拡張機能が見つかるまで、拡張機能を 1 つずつ再度追加してみてください(その後、わかったことを Looker Studio コミュニティ フォーラムに投稿することをご検討ください)。
統合に関する問題
統合に関する一般的な問題は、次のバケットに分類できます。
- 不適切な結合
- データソースの接続がない、または正しくない
- 統合の結果に関する問題や混乱
不適切な結合に関するエラーや症状の例
1 つ以上の結合の設定が完了していません結合条件が指定されていない結合の設定が 1 つ以上あります結合キーが不完全です。選択した各データソースについて、すべての結合キーに対して結合キーフィールドを指定する必要があります。- フィールドが「欠落」していて結合条件で使用できない(ピンク色)
解決手順
- 結合の設定を編集します。
- 統合の各設定に結合条件と結合演算子が含まれていることを確認します(クロス結合を使用していて、結合条件を使用できない場合を除きます)。
- フィールドが欠落している場合: 該当するフィールドを削除するか、結合設定の各ペアに対応するフィールドがあることを確認します。
データソースの接続がない、または正しくない場合のエラーや症状の例
1 つ以上のテーブルでデータソースが指定されていません。解決手順
データソースが欠落しているテーブルを再接続します。Google アナリティクス 4 の割り当ての上限に達した場合
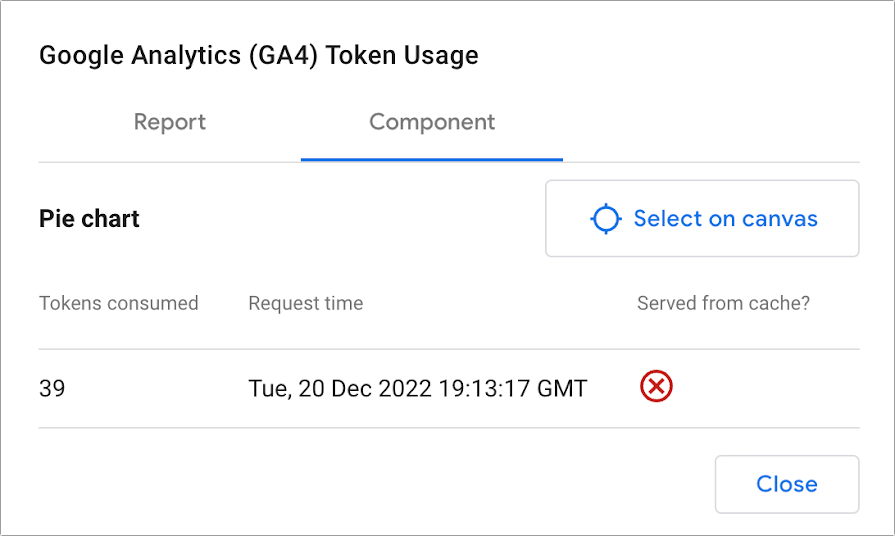
2022 年 11 月 7 日より、Google アナリティクス 4 のデータに接続する Looker Studio レポートに、Google Analytics Data API(GA4)の割り当てが適用されます。レポートの GA4 データ使用量は、[Google アナリティクス トークンの使用状況] ダイアログで確認できます。
トークンの使用状況を表示する
- Looker Studio レポートを編集します。
- レポートの全体的なトークン使用量を確認するには、レポート キャンバスを右クリックして、[Google アナリティクス トークンの使用状況] を選択します。
- 特定のコンポーネントのトークンの使用状況を確認するには、コンポーネントを右クリックして [Google アナリティクス トークンの使用状況] を選択します。
Google アナリティクス 4 トークンの全体的な使用状況については、次の情報を確認できます。
- レポート全体、または現在のユーザー セッションのページあたりの使用されたトークン割り当て量
- 割り当てに達するまでに使用可能な残りのトークン割り当て量
- トークン割り当て量はグラフごとに消費され、トークンの消費量が多い順に並べ替えられます
特定のコンポーネントによるトークンの使用状況については、次の情報を確認できます。
- 各リクエストで消費されたトークン割り当て量
- 各リクエストが終了した時刻
- リクエストがキャッシュから配信されたかどうかについて、赤色の X はリクエストがキャッシュから配信されなかったことを示し、丸で囲まれた緑色のチェックマークはリクエストがキャッシュから配信されたことを示します。
割り当て超過エラー
これらの割り当ての上限に達したレポートには、次のいずれかのエラー メッセージが表示される可能性があります。
同時リクエストの数が割り当ての上限に達しました。同時リクエストの数を減らして送信してください。このプロパティで過去 1 日間に送信されたリクエストが多すぎます。この Google アナリティクス プロパティで過去 1 時間以内に送信されたリクエストが多すぎたため、エラーが発生しました。このプロパティで過去 1 時間以内に送信されたリクエストが多すぎます。このプロパティには Google アナリティクスへのアクセス権がありません。このプロパティで過去 1 時間以内に送信されたリクエストが多すぎて、割り当ての上限に達する可能性があります。このプロジェクトまたはプロパティで過去 1 時間以内に送信されたリクエストが多すぎます。
解決手順
このようなエラーが発生した場合は、次の方法で、Google アナリティクス 4 からクエリされるデータの量を減らすことができます。以下の手順で Looker Studio のデータ キャッシュ メカニズムに対する依存度を高めることによって、割り当てが上限に達する事態を回避できます。
- まず、閲覧者の認証情報ではなく、データソースのオーナーの認証情報を使用することで、データがクエリされてトークンが割り当てられる代わりに、キャッシュされたデータが使われる可能性を高めます。閲覧者の認証情報を使用している場合は、オーナーの認証情報に切り替えることをご検討ください。
- レポートで複数の Google アナリティクス 4 データソースを使用している場合は、可能であればそれらを 1 つの再利用可能なデータソースに統合することをご検討ください。これにより、データがクエリされてトークンが使われる代わりに、キャッシュされたデータが使用される可能性も高まります。
- レポートへのトラフィックを減らします。レポートを共有するユーザーの数を減らすことをご検討ください。また、トラフィックの多いウェブサイトにレポートを埋め込まないようにします。
- 各ページのグラフの数を減らします。
- Google アナリティクス 4 のデータを抽出し、Google アナリティクス 4 のデータソースの代わりに抽出されたデータを使用します。
- 注: データの抽出は、上限に達した割り当てが更新されるまで待ってから行う必要があります。これには、上限に達した割り当てに応じて、24 時間程度かかることがあります。
- アナリティクス データを BigQuery にエクスポートし、BigQuery コネクタを使用して Looker Studio でそのデータを視覚化します。
- アナリティクス 360 にアップグレードします。
- パートナー コネクタの使用をご検討ください。
より複雑な問題が発生した場合のトラブルシューティング戦略
Looker Studio に関する不明確な問題を診断する場合は、まず問題が発生している場所を特定します。
たとえば、その問題が一般的または限定的なものか、すべてのレポートまたは特定のレポートで発生するか、すべてのコンポーネント タイプまたは特定のコンポーネントでのみ発生するか、複数のブラウザまたは特定のブラウザの特定のバージョンでのみ見られるものなのかを特定します。
関連情報: Looker Studio の使用要件
次の手順では、変動要因の数を減らします。
大まかにいって、これは、データを最小化したりレポートを簡素化したりすることで、問題の要因をできるだけ絞り込むことを意味します。たとえば、データに問題があると思われる場合は、フィルタを使用するかデータセットを編集して、行数を半分に減らしてみてください。これで問題が解決し、残り半分の行を含めた場合に問題が再発する場合は、この残り半分のデータに問題があることがわかります。
同様に、特定のグラフに問題がある場合は、最小数のフィールドと最も単純なスタイル オプションを使って単純なグラフを作成してから、グラフの複雑性を徐々に高めて、特定のフィールドや設定による問題かどうかを確認します。
Google に問題を報告
問題を解決できない場合は、Google までご報告ください。問題の診断に役立てるため、以下の情報を提供できるようにご準備ください。
- 問題に関する詳細な説明。
- 問題の再現手順。
- 表示されるエラー メッセージまたはエラー ID。
- 問題を示すテストレポートまたはデータソースへのリンク。
エラー ID について
エラー ID(通常は 8 文字の数字と文字を組み合わせたもの)が表示された場合は、Google へのレポートに必ず含めてください。エラー ID は、Google のエンジニアがログでエラーをすばやく見つけるのに役立つ一意の識別子です。特定のエラー条件に静的にマッピングされるのではなく、動的に生成されるため、エラーの特定のインスタンスに対応します。つまり、エラーが発生するたびに異なる ID が生成されるということです。テストレポートについて
上述のとおり、共有するテストレポートの複雑さを軽減していただくと、Google はより簡単にトラブルシューティングを行えるようになります。可能であれば、作成するテストレポートはできるだけ簡潔なものにしてください。たとえば、元のレポートのコピーを作成してから、問題を示すためには不要なページ、グラフ、フィルタなどのコンポーネントを削除するとよいでしょう。
-
Looker Studio のパフォーマンスを改善する
Looker Studio レポートでは、フィルタの適用や期間の変更など閲覧者が加えた変更を読み込み、応答するのにかかる時間が、次のようなさまざまな要因によって変わります。
- 基になるデータセットのパフォーマンス
- レポートのビジュアリゼーションによってクエリが実行されているデータの量
- 上記クエリの複雑さ
- ネットワーク遅延
こうした要因の中には、ユーザー自身(または Looker Studio)では制御できないものもあります。たとえば、基盤となるデータ プラットフォームの応答性を向上させたり、ネットワーク接続の速度を上げたりするためにユーザーができることはほとんどありません。ただし、Looker Studio でレポートのパフォーマンスを調整する方法はいくつかあります。
パフォーマンスの調整には、速度と応答性のトレードオフが関係する場合もあれば、最新のデータとユーザーによるカスタマイズのトレードオフが関係する場合もあります。ここで紹介するヒントは、すべてのお客様のユースケースに適しているものではありません。データの更新頻度を調整する
Looker Studio では、パフォーマンス調整機能の一部をすでに内部で利用しています(Google では、これらの機能の改善に継続的に取り組んでいます)。たとえば、Looker Studio の場合、レポートのパフォーマンスを向上させるためにキャッシュと呼ばれる一時的なストレージ システムからデータを取得します。キャッシュ データを取得するほうが、基になるデータセットから直接取得するよりも処理時間がかなり短くなる場合があります。また、キャッシュ データを取得すると、データセットから直接提供する必要のあるクエリの数が減るため、BigQuery などの有料サービスの費用を最小限に抑えることができます。
キャッシュ内のデータが更新される頻度をデータの更新頻度と呼びます。実際の更新頻度はコネクタによって異なりますが、可能であれば、更新間隔を長めに設定することをおすすめします。次の更新までの間に繰り返し実行されるクエリの回答にはキャッシュが使用されるため、間隔が長いほうがレポートのパフォーマンスが向上します。ただし、トレードオフとして、最新情報を取得できない可能性があります。
詳しくは、データの更新頻度を管理するをご覧ください。
抽出されたデータソースを使用する
デフォルトでは、データソースと基になるデータセットのライブ接続は維持されています。上記のキャッシュが期限切れになった場合や、キャッシュでは対応できない新しいクエリが実行された場合、Looker Studio はデータセットにアクセスして対象データを取得します。このような時間のかかるデータ取得を回避するには、既存のデータソースから最大 100 MB のデータを、抽出済みデータソースとして抽出します。
必要な特定のフィールドを選択してフィルタを適用し、期間を追加してデータのスナップショットを作成します。スナップショットを作成すると、元のデータにライブ接続した状態よりも、レポートや原因分析の読み込みが速くなり、応答性が高くなることがあります。この場合のトレードオフとして、抽出されたデータソースは静的な状態になります。つまり、データソース自体が更新されるまでレポートのデータは変わりません。ただし、抽出されたデータソースを自動的に更新するようスケジュールを設定できるため、それほど問題とならない可能性があります。
詳しくは、データの抽出に関する記事をご覧ください。
BI Engine を使用して BigQuery データソースを高速化する
BigQuery BI Engine は、高速なメモリ内分析サービスです。BI Engine を使用すると、BigQuery に保存されたデータを分析できます。クエリ応答時間は 1 秒未満で、同時実行性にも優れています。
BI Engine は Looker Studio と統合されるため、データ探索や分析がスピードアップします。BI Engine を使用すると、パフォーマンス、スケーリング、セキュリティ、データの鮮度を損なうことなく、Looker Studio で高機能かつインタラクティブなダッシュボードとレポートを作成できます。
詳しくは、BI Engine を Looker Studio で使ってみるをご覧ください。
-
データ内のハイパーリンク
表を使ってデータ内にクリック可能なリンクを表示できます。そうしたリンクは、次の 2 通りの方法で取得できます。
- URL タイプのフィールドを使ってデータセットから直接取得する
- HYPERLINK 関数を使ってリンクを生成する
URL のフィールド タイプ
データソースを作成するときには、Looker Studio がデータセット内の有効な URL を検出し、そのディメンションに URL のフィールド タイプを割り当てます(URL が Looker Studio で自動的に検出されない場合は、フィールド タイプを URL に手動で設定できます)。
URL フィールドを使うと、グラフ内に完全なリンクが表示されます。表内に表示されるこのリンクはクリック可能です。
HYPERLINK 関数
HYPERLINK 関数を使用すると、計算フィールドでリンクを作成できます。HYPERLINK 関数は、URL とリンクのラベルを入力として受け取ります。その結果、表で表示される場合にはクリック可能なリンクが出力されます(他のグラフでは、リンクテキストはクリックできません)。
URL フィールドと HYPERLINK 関数の両方に対応しているのは、特定のプロトコルだけです。詳しくは HYPERLINK に関する記事をご覧ください。
-
「比率指標を集計できませんでした」というエラーの意味
概要
次のエラー メッセージが表示されることがあります。
リクエストに含まれる比率指標を集計できませんでした。別の指標を選択してください。このエラーは、集計済みの比率指標を使って実行することができない操作を Looker Studio でリクエストした際に表示されます。たとえば、比率指標を含むグラフに計算フィールドに基づくフィルタを適用した場合などが該当します。
解決策として、グラフで比率以外のフィールドを選択する(クリック率ではなくインプレッションを使用するなど)か、フィルタを削除または変更します。
この記事の内容:詳細
比率指標は、2 つ以上の値の相対的な大きさを示します。たとえば、Google 広告のクリック率(CTR)は、広告がクリックされた回数を広告の表示回数で割ったものです。また、Google アナリティクスでは、1 ページのみのセッション数をすべてのセッション数で割ったものを直帰率とするほか、サイトにアクセスして新しいセッションを開始したユーザーの人数とページビュー数を比較し、その割合を閲覧開始数 / ページビュー数として計算します。
Looker Studio では、商品の比率を再計算する必要がある比率指標を含むグラフにフィルタを適用すると、上記のエラーが発生します。
この問題を理解する 3 つのポイント
1)Google アナリティクス、Google 広告、YouTube、Google マーケティング プラットフォームなどのデータセットからのデータは、Looker Studio に到達した時点で、すでに集計されています。たとえば、Looker Studio が CTR(クリック率)などの Google 広告指標をリクエストすると、データはすでに適切な集約タイプに処理されています。
2)上記の理由により、計算フィールドの関数は集計後のデータに適用されます。元データに戻り、その指標のすべての固有のインスタンスを調べることはできません(また、調べても基本的に意味はありません)。たとえば、Google 広告データソースで
SUM(Impressions)の数式を使って計算フィールドを作成しようとすると、次のエラーが発生します。再集計の指標はサポートされていません。これは、インプレッション数がすでに集計されて(おり、[自動] の集計タイプを変更できなくなって)いるためです。
集計されていないデータを Looker Studio に送信できる Google スプレッドシート、MySQL、BigQuery などのデータソースの場合、必ずしもこのエラーが発生するとは限りません。たとえば、スプレッドシートにインプレッションの元データがある場合は、SUM 関数を使用してすべてのデータを合計したり、AVG 関数を使用して平均を計算したりすることができます。3)一貫性を保つために、Looker Studio の計算フィールド関数は、元になるシステムがその関数をネイティブにサポートしていない場合でも、すべてのデータソース タイプで使用できます。たとえば、CONCAT 関数を使って複数の値を結合する場合、元になるシステムに独自の CONCAT 関数がないデータソースでも関数を実行でききます。これは、元になるシステムに CONCAT 関数を「プッシュダウン」する代わりに、Looker Studio がデータをリクエストして独自に連結を実行するためです。
集計の失敗例
「
比率指標を集計できませんでした」というエラーについて理解を深めるため、CONCAT の例をさらに考えてみましょう。次の式を使用して、Google 広告データソースで「キャンペーン : クリックタイプ」と呼ばれる計算フィールドを作成したとします。
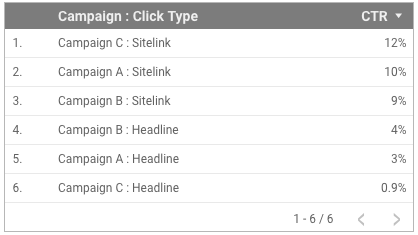
CONCAT(キャンペーン, " : ", クリックタイプ)Looker Studio は、キャンペーンとクリックタイプのクエリを個別に発行し、連結を実行します。結果はグループ化されているため、レコードの重複はありません。
グラフでその連結フィールドを使用し、そこに含まれる指標が適切に集計されるようになります。たとえば、表では「キャンペーン : クリックタイプ」をディメンションとして、「CTR」を比率指標として使用できます。
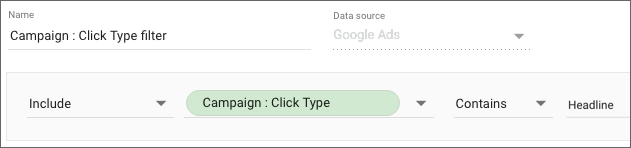
ここで、クリックタイプが「
見出し」であるレコードのみを表示するようにフィルタを適用したとします。するとグラフは破損されてしまいます。
破損される理由
フィルタを適用すると、「キャンペーン : クリックタイプ」に「見出し」が含まれている場合にのみ返されるレコードを表示するようリクエストされます。このフィールドは 2 つのディメンションを連結したものです。このリクエストを満たすには、この 2 つのディメンションを再取得してからフィルタを適用する必要があります。問題は、比率指標である CTR が表に存在することです。Google 広告の比率指標は、Looker Studio がリクエストする前に計算されますが、Looker Studio には元データにアクセスする方法がなく、連結されたフィールドに「見出し」を含むレコードの新しい比率を再計算することができません。
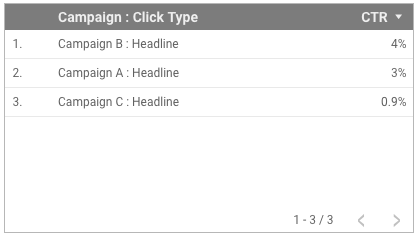
解決方法
このような場合の解決方法は、表示しようとしているデータによって異なります。この例では、CTR 指標をインプレッションなどの比率以外の指標に置き換えることができます。または、連結された「キャンペーン : クリックタイプ」フィールドでフィルタを適用する代わりに、標準の「クリックタイプ」フィールドにフィルタを適用することで、同じ結果を得られます。
グラフは正常に表示されます。
関連資料
-
サンプル レポート
サンプル レポート:現在、この情報は英語でのみご覧いただけます。
レポート ユーザー Looker Studio へようこそ(最初にご確認ください)
Looker Studio のレポートの閲覧、編集、作成について学ぶことができます。
新規ユーザー フィルタ オプションの例
フィルタ オプションのさまざまなスタイルを紹介するレポートです。Google スプレッドシートと Google アナリティクスの、2 つのソースからデータを取り込んでいます。レポートの上部にフィルタ オプションがあり、設定を変更して結果を確認できるようになっています。
すべてのユーザー データの色分けの例
2 種類あるデータの色分け方法を確認できるレポートです。
- ディメンションの値に基づいて配色する。たとえば、「フランス」を常に赤色で表示できます。これが新規レポートのデフォルト設定になります。
- ディメンションのデータの順序に基づいて配色する。たとえば、1 つ目のデータ系列を常に青色で表示できます。
すべてのユーザー レイアウト グリッドを使ったレポート デザイン
グリッドサイズを調整して統一感のあるレポートをデザインする方法を紹介します。
キャンバスのグリッドサイズの最小値は 10 ピクセルです。グリッドサイズは [グリッドの設定] で調整できます。グリッドサイズを大きくすると、グラフ、コントロール、その他のコンポーネントのレイアウトが容易になります。
このレポートには Google アナリティクスのデータ管理コンポーネントが含まれており、アナリティクスのデータを表示するレポートのテンプレートとして使用できます。すべてのユーザー 関数
関数を使用してデータの累積合計をレコードごとに算出すると、データ全体に対するそれぞれの貢献度を把握するのに役立ちます。
すべてのユーザー 「レポートレベルのコンポーネントの位置」について理解する
疑問:
レポートレベルのコンポーネントが表示されなくなってしまうのですが?
解決策:
[レポートレベルのコンポーネントの位置] を [上] に変更しましょう。
すべてのユーザー 座標軸の逆転配置
座標型のグラフで X 軸および Y 軸の向きを切り替える方法を紹介したレポートです。
すべてのユーザー データの統合の例: クラス、生徒、成績
このデモレポートでは、ビジネスに関する質問に対する答え(例: 学校管理者の場合、生徒、生徒が参加しているクラス、生徒が収めている成績に関する分析情報)を得るために、異なるデータソースにあるデータを解釈して視覚化する方法について示しています。
上級ユーザー マップチャートで緯度経度と都市名を併記する
疑問:
マップチャートで、データを最大限の解像度で表示できるよう緯度経度の情報を使用しつつ、都市名も表示するには?
解決策:
計算フィールドを使って緯度経度の情報と都市名を結合します。例: CONCAT(Lat Long , "(", City,")")
上級ユーザー HYPERLINK 関数の例
ハイパーリンク フィールドの使用方法を示したレポートです。ハイパーリンクを使用すると、表内にクリック可能なリンクを作成できます。
ハイパーリンク フィールドの作成には、
HYPERLINK関数を使用します。関数の 1 つ目のパラメータには URL を、2 つ目のHYPERLINKパラメータにはテキスト フィールド(またはテキストを返す式)を指定しましょう。上級ユーザー 画像リンクの例
画像リンク フィールドの使用方法を示したレポートです。画像リンクを使用すると、表内にクリック可能な画像を追加できます。
画像リンク フィールドの作成には、
HYPERLINK関数を使用します。1 つ目のパラメータには URL を、2 つ目のHYPERLINKパラメータには画像フィールド(または画像への有効なリンクを含む IMAGE 関数)を指定しましょう。上級ユーザー -
欠落データ
レポートやデータソースに目的の情報がすべて表示されない場合は、以下の点を確認してください。
レポートでのデータの欠落
データがキャッシュされていますか。
最近追加されたデータがレポートに表示されない場合、レポートを編集して右上の
をクリックすると、キャッシュを更新できます。この機能を使用するには、レポートの編集者である必要があります。
データがフィルタリングされていますか。
レポートを編集し、[リソース] > [追加されたフィルタを管理] をクリックして、レポートにフィルタ プロパティが含まれているかを確認します。含まれている場合は、それがデータの欠落の原因でないことを確かめるために、その設定を確認してください。
データソースでのフィールドの欠落
データソースがデータセットと同期されていない状態ですか。
最近追加されたフィールドや列がデータソースに表示されない場合、データソースを編集し、左下の [フィールドを更新] をクリックすると追加できます。詳細
Google スプレッドシートのデータソースで行や列が欠落していますか。
上記の方法でフィールドを更新してもスプレッドシートのデータソースで行やデータが欠落している場合は、適切な範囲とオプションがデータソースの接続に含まれていることを確認してください。この操作を行うには、データソースのオーナーである必要があります。
- データソースを編集します。
- 左側の [接続を編集] をクリックします。
- 右側の接続オプションを確認します。指定した範囲にすべてのデータが含まれていることと、該当する場合は、フィルタリングされた非表示のフィールドが含まれていることを確認してください。
スプレッドシートのコネクタ オプション。
コネクタに関する制限ですか。
Google サービスの多くのコネクタを含む固定スキーマに基づくコネクタでは、基になるデータセットの一部のフィールドが提供されないことがあります。元のサービスに含まれているフィールドがデータソースで欠落している場合は、そのフィールドが Looker Studio でサポートされていない可能性があります。フィールドがすでにリクエストされているかどうかを確認するには、公開バグトラッカーを参照し、リクエストされていない場合は、機能のリクエストを提出できます。
-
負の数をグラフで表示する
2019 年 1 月 16 日の時点では、軸の最小値のデフォルト値は [(自動)] のため、グラフのバージョンが古い場合は、これを変更するだけで済みます。
以前は、デフォルトの最小値は「0」に設定されていました。
グラフに負の値の指標を表示するには、[軸の最小値] のオプションを「(自動)」に設定します。
- レポートを編集モードに切り替えます。
- グラフを選択します。
- [スタイル] パネルを選択します。
- 主軸の設定を探します。デフォルトのグラフの場合、これは左軸になりますが、グラフのカスタマイズ方法によっては、右軸や下軸になることもあります。
- 現在の設定を削除して、[軸の最小値] を [(自動)] に変更します。
以下は、軸の最小値が「0」の場合と「(自動)」の場合のグラフの表示例です。
- 一番上のグラフのデータには、負の値と正の値が混在しています。
- 左側のグラフは、[軸の最小値: 0] を使用するように設定されています。
- 右側のグラフでは、[軸の最小値:(自動)] が使用されています。
- 最後の 2 つのディメンション値(「Green」と「Blue」)がグラフでどのように表示されているかに注目してください。
- 真ん中のグラフのデータは、正の値のみが含まれています。この場合、「0」と「(自動)」のどちらに設定しても、違いはありません。
- 下のグラフのデータには負の値のみが含まれています。ここで、右側の「(自動)」の設定を使用すると、ビジュアル表示が正しく行われます。
-
行ごとに複数のメールアドレスでフィルタする
前提条件
このソリューションでは、次に挙げる Looker Studio の概念やタスクを使用します。メールアドレスによるフィルタは、ログインしている閲覧者のアドレスと、有効なメールアドレスを含むデータソースのフィールドを比較することによって行われます。つまり、閲覧者のメールアドレスが、データの各行にあるアドレスに一致するかどうかが確認されます。
次のようなデータがあるとします。
メールアドレス データ alan@example.com abc mary@example.com cde alan@example.com efg mary@example.com ghi メールアドレスでデータをフィルタしている場合、alan@example.com がフィルタされたレポートを閲覧すると、
「abc」、「efg」のみが表示されます。mary@example.com が同じレポートを閲覧した場合には、「efg」と「ghi」が表示されます。これは、閲覧者とデータが 1 対 1 の関係にある場合は問題ありません。しかし、manager@example.com にもデータが見えるようにしたい場合にはどうすればよいでしょうか。つまり、複数のデータ行を、複数のユーザーに表示したい場合です(これは「多対多の関係」と呼ばれます)。
メールアドレスによるフィルタは、1 行に含まれるメールアドレスが 1 件だけの場合にのみ機能します。そのため、単純にメールアドレスのフィールドに複数のメールアドレスを挿入することはできません。たとえば、次の場合は機能しません。
メールアドレス データ alan@example.com, manager@example.com, vp@example.com, bigwig@customer.com abc 解決策: データの統合を使用する
共通のフィールドを結合キーとして使用してメールアドレスのテーブルとデータを結合することによって、メールアドレスとデータの間に多対多の関係を作ることができます。
果物店の例
あなたは、果物を生産する会社を経営しており、営業担当者がそれぞれの担当している複数の果物店での営業成績を自身で確認できるようにしたいと考えています。各営業担当者は複数の店舗を担当でき、1 店舗に複数の担当者がいる場合もあります。営業担当者が各自のデータだけを閲覧できるようフィルタするには、次の方法が使用できます。
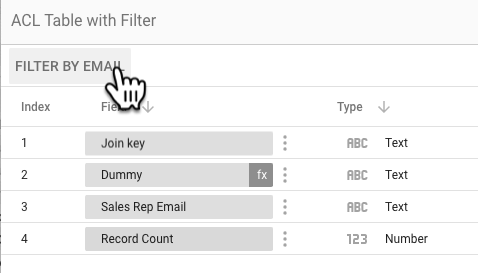
ステップ 1: アクセス制御リストのテーブルを作成する
このステップでは、アクセス権を与える営業担当者のメールアドレスと、データ統合の結合キーとして使用するデータ フィールド(果物店の名前)を対応させた、アクセス制御リスト(ACL)のテーブルを作成します。
営業担当者のメールアドレス 結合キー salesrep1@example.com 果物店 A salesrep2@example.com 果物店 A salesrep1@example.com 果物店 B salesrep2@example.com
果物店 C アクセス制御リスト(ACL)のテーブル
営業担当者 1 は、果物店 A と果物店 B のデータを表示でき、営業担当者 2 は果物店 A と果物店 C のデータを表示できます。
ステップ 2: データテーブルを作成する
データテーブルは、営業担当者による各果物店への販売数を記録したものです。
このテーブルには営業担当者のメールアドレスは含まれず、結合キーと同じ値(果物店名)だけが含まれます。また、結合キーフィールドの名前はここでは不要です。統合処理では、フィールド名ではなくデータに基づいて結合が行われます。果物店 果物 販売数 果物店 A リンゴ 50 果物店 A バナナ 26 果物店 A オレンジ 20 果物店 A 洋ナシ 93 果物店 B リンゴ 98 果物店 B バナナ 86 果物店 B オレンジ 7 果物店 B 洋ナシ 85 果物店 C リンゴ 21 果物店 C バナナ 61 果物店 C オレンジ 3 果物店 C 洋ナシ 78 データテーブル
ステップ 3: ACL テーブルにメールフィルタを適用する
ACL テーブルのデータソースを編集し、「営業担当者のメールアドレス」フィールドをフィルタとして選択します。
ステップ 4: ACL テーブルとデータテーブルを統合する
メールフィルタを適用せずに ACL テーブルとデータテーブルを統合すると、両方の営業担当者のレコードがすべて表示されます。一方、メールフィルタを適用して ACL テーブルとデータテーブルを統合すると、レポートを閲覧している営業担当者が誰であるかによってデータがフィルタされます。各営業担当者には、レポートは次のように表示されます。
営業担当者 1 の場合:
データ 果物 販売数 果物店 A リンゴ 50
果物店 A バナナ 26
果物店 A オレンジ 20
果物店 A 洋ナシ 93
果物店 B リンゴ 98
果物店 B バナナ 86
果物店 B オレンジ 7
果物店 B 洋ナシ 85
営業担当者 2 の場合:
データ 果物 販売数 果物店 A バナナ 26
果物店 A オレンジ 20
果物店 A リンゴ 50
果物店 A 洋ナシ 93
果物店 C バナナ 61
果物店 C オレンジ 3
果物店 C リンゴ 21
果物店 C 洋ナシ 78
-
無効なフィールド名に起因するエラーを解決する
問題
レポートのグラフに「無効なフィールド名に起因するエラー。」と表示される
破損される理由
一部のコネクタでは、Looker Studio で処理できないフィールド名の文字に対応しています。たとえば Looker Studio では、Unicode 文字と特殊文字(アンパサンド、コロンなど)を含む BigQuery フィールドは処理されません。
詳しくは、BigQuery の柔軟な列名をご確認ください。
解決策
この問題を解決するには、基盤のデータセットのフィールド名を変更し、データソースを再接続します。
-
10 個を超える AND / OR フィルタをグラフに追加する方法
前提条件
このソリューションでは、次に挙げる Looker Studio の概念 / タスクを使用します。この制限に対しては、次のような対応策があります。
フィルタ条件を別のタイプに更新する
この制限の対応策として、より包括的な種類のフィルタにフィルタ条件を変更する方法があります。
たとえば、11 個の値と一致可能なフィールドが必要な場合は、
INフィルタタイプを使用して、それらの値をそれぞれリストに含めることができます。別の例として、商品名を含むフィールドについて考えてみましょう。フィルタを作成して、A から L の 12 個のそれぞれの文字で始まるすべての商品を返したい場合、適切な正規表現の構文を使用する RegExp マッチタイプのフィルタを適用します。この例では、構文は
REGEXP_MATCH(field, "^[A-L].*"のようになります。フィルタ条件を新しいフィールドに移動する
別の対応策として、条件を別の計算フィールドに移動し、その新しいフィールドでフィルタリングする方法もあります。計算フィールドでは、含めることができる論理条件の数にこの同じ制限は適用されません。
たとえば、11 個の異なるフィールドがあり、そのうちのいずれかに特定のエラー文字列が含まれているかどうかをチェックするフィルタを作成したいとします。
この条件をチェックするために必要な 11 個の OR 条件を持つ新しいフィールドを作成できます。数式は次のようになります。
CONTAINS_TEXT(log_field_1, "error")
OR
CONTAINS_TEXT(log_field_2, "error")
OR
CONTAINS_TEXT(log_field_3, "error")
OR
CONTAINS_TEXT(log_field_4, "error")
OR
CONTAINS_TEXT(log_field_5, "error")
OR
CONTAINS_TEXT(log_field_6, "error")
OR
CONTAINS_TEXT(log_field_7, "error")
OR
CONTAINS_TEXT(log_field_8, "error")
OR
CONTAINS_TEXT(log_field_9, "error")
OR
CONTAINS_TEXT(log_field_10, "error")
OR
CONTAINS_TEXT(log_field_11, "error")
この数式フィールドには、
TrueまたはFalseと評価されるブール値フィールド タイプが作成されます。最後に、この新しいフィールドに対して
Trueでフィルタリングするフィルタを作成します。