Fördjupa dig i din data med den mycket anpassningsbara och flexibla tekniken för utforskning med fritt format. Med utforskning med fritt format kan du
- visualisera data i en tabell eller ett diagram
- strukturera och ordna rader och kolumner i tabellen som du vill
- jämföra flera mätvärden sida vid sida
- skapa kapslade rader för att gruppera data
- finjustera utforskningen med fritt format med hjälp av segment och filter
- skapa segment och målgrupper utifrån vald data.
Skapa en utforskning med fritt format
- I Utforska Välj mallen Fritt format under Starta en ny utforskning.
Föregående länk öppnas till den Analytics-egendom som du besökte senast. Du kan ändra egendom med hjälp av egendomsväljaren. Du måste vara analytiker eller högre för att Skapa en utforskning med fritt format.
- Välj hur du vill visa data under Visualisering:
|
|
Läs mer om hur du skapar och redigerar utforskningar.
Exempel på utforskning med fritt format
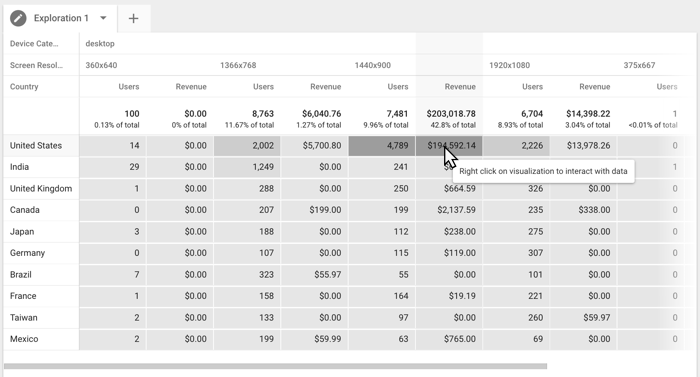
I exemplet nedan undersöker vi förhållandet mellan Enhetskategori och Skärmupplösning efter Land, mätt i antal Användare och Intäkt. Tabellen visar att även om skärmupplösningen för de flesta användare med stationära datorer är 1 366 × 768 genereras huvuddelen av intäkterna från användare med skärmar på 1 440 × 900. Du kan skapa ett segment utifrån denna datapunkt och använda det för att undersöka målgruppens beteende mer ingående.
Du kan också visa data med hjälp av ett antal olika visualiseringar. Följande exempel visar ett linjediagram som jämför segmenten Mobiltrafik och Organisk trafik, tillämpade på föregående datatabell. Du kan välja olika visualiseringar för att få olika insikter om personerna som besöker din webbplats eller app.

Avvikelseidentifiering
Genom att använda avvikelseidentifiering i ett linjediagram kan du upptäcka avvikande värden i din data. Alternativet är aktiverat som standard i panelen Flikinställningar och du kan ställa in identifieringsmodellen med följande två inställningar:
- Träningsperiod (senaste dagarna) avser antalet dagar före det valda datumintervallet som används av modellen för att beräkna mätvärdets förväntade värde.
- Om det valda datumintervallet till exempel är de första tio dagarna i månaden och du anger en träningsperiod på sju dagar använder avvikelseidentifieringsmodellen data från de sju dagarna före månadens början.
- Känslighet anger sannolikhetsgränsen under vilken avvikande data rapporteras. Känsligheten påverkar inte hur modellen ”tänker”, den anger bara hur data ska märkas. Sannolikheten för att en punkt inträffar vid ett visst värde förutses av modellen och påverkas inte av känsligheten.
- En känslighet på 5 % innebär till exempel att varje punkt som förekommer med en sannolikhet på mindre än 5 % betraktas som avvikande. Därför kan en modell med högre känslighet resultera i att mer data rapporteras som avvikande.
När avvikelseidentifieringsmodellen har definierats tillämpar Utforskningar en bayesiansk tillstånds-/tidsseriemodell på träningsdata för att förutse värdet på det mätvärde som visas i tidsserien.
Slutligen flaggar Utforskningar datapunkten som en avvikelse med hjälp av ett statistiskt signifikanstest med gränsvärden för p-värdet som baseras på den valda känsligheten.
Ställa in utforskningar med fritt format
Ställ in utforskningen med fritt format med hjälp av dessa alternativ:
| Vanliga alternativ | Beskrivning |
|---|---|
| Visualisering |
Växla mellan diagramtyper. |
| Segmentjämförelse | Använd upp till fyra segment i utforskningen. |
| Filter | Begränsa informationen som visas i utforskningen utifrån villkoren du anger. Filtersatser tillämpas med OCH-logik. |
| Tabellalternativ | |
| Pivot | Visa segment i tabellen som rader eller kolumner. |
| Rader | Visa upp till fem dimensioner som rader i tabellen. |
| Första raden | Välj tabellens första rad. |
| Visa rader | Ange antalet rader som ska visas i tabellen. |
| Kapslade rader | Visa dimensioner i en kapslad hierarki med upp till tio värden per kapslad dimension. |
| Kolumner | Visa upp till två dimensioner som kolumner i tabellen. Om du använder flera dimensioner skapas kolumngrupper. |
| Första kolumngruppen | Ange den inledande kolumngruppen i tabellen. |
| Visa kolumngrupper | Ange det antal kolumngrupper som ska visas i tabellen. |
| Värden | Visa upp till tio mätvärden i tabellen. |
| Celltyp | Visa mätvärden som vanlig text, stapeldiagram eller värmekartor. |
| Alternativ för cirkeldiagram | |
| Fördelning | Dimensionen som används för att tillhandahålla de uppdelade dataserierna för visualiseringen. |
| Radgräns | Ange antalet dataserier som ska visas i visualiseringen. |
| Värden | Visa ett enskilt mätvärde i diagrammet. |
| Alternativ för linjediagram | |
| Detaljnivå | Ange datumintervall för diagrammet. Veckointervallet börjar på söndagen. Månadsintervallet börjar den första dagen i månaden. |
| Fördelning | Dimensionen som används för att tillhandahålla de uppdelade dataserierna för visualiseringen. |
| Rader per dimension | Ange antalet dataserier som ska visas i visualiseringen. |
| Värden | Visa ett enskilt mätvärde i diagrammet. |
| Avvikelseidentifiering | Aktivera eller inaktivera avvikelseidentifiering. Läs mer nedan. |
| Träningsperiod (senaste dagarna) | Öka eller minska det tidsintervall som används för att granska din data. Längre träningsperioder kan ge större exakthet. |
| Känslighet | Ange tröskelvärdet för sannolikhet. Avvikande data som understiger detta värde rapporteras. Ett högre känslighetsvärde kan resultera i att fler avvikelser rapporteras. |
| Alternativ för punktdiagram | |
| Fördelning | Dimensionen som används för att tillhandahålla de uppdelade dataserierna för visualiseringen. |
| Y-axel | Mätvärdet som används på den vertikala axeln |
| X-axel | Mätvärdet som används på den horisontella axeln |
| Alternativ för geografiska kartor | |
| Geografisk uppdelning | Platsdimensionen som används för att tillhandahålla de uppdelade dataserierna för visualiseringen. |
| Punkter per dimension | Ange antalet datapunkter som ska visas i visualiseringen. |
| Värden | Visa ett enskilt mätvärde i diagrammet. |