Dyk dybere ned i dine data ved hjælp af den fleksible udforskningsteknik i frit format. Med udforskning i frit format kan du gøre følgende:
- Visualisere data i en tabel eller graf.
- Arrangere og ordne rækkefølgen af rækker og kolonner i tabellen, som du vil.
- Sammenligne flere metrics side om side.
- Oprette indlejrede rækker for at gruppere dataene.
- Justere udforskningen i frit format ved hjælp af segmenter og filtre.
- Oprette segmenter og målgrupper fra de valgte data.
Opret en udforskning i frit format
- Log ind på Google Analytics.
- Klik på
Udforsk til venstre.
- Vælg skabelonen Frit format øverst på skærmen.
- Vælg, hvordan du vil vise dataene, under VISUALISERING:
|
|
Få flere oplysninger om, hvordan du opretter og redigerer udforskninger.
Eksempel på en udforskning i frit format
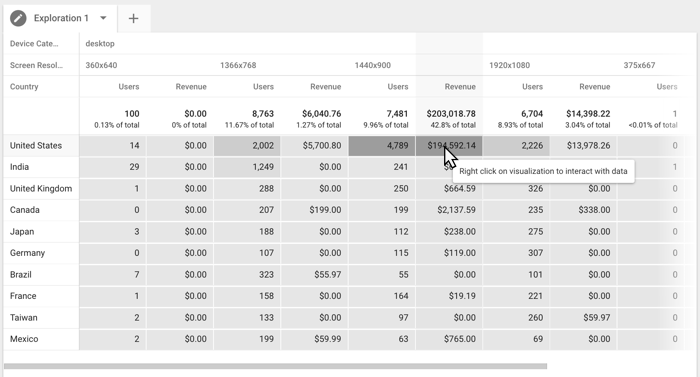
I eksemplet nedenfor undersøges forholdet mellem Enhedskategori og Skærmopløsning efter Land målt ud fra antal Brugere og Omsætning. Som det fremgår af tabellen, benytter de fleste computerbrugere skærmopløsningen 1.366 x 768, men størstedelen af omsætningen genereres af brugere, der benytter skærmopløsningen 1.440 x 900. Du kan oprette et segment ud fra dette datapunkt og bruge det til at undersøge denne målgruppes adfærd nærmere.
Du kan også få dataene vist i forskellige visualiseringer. I følgende eksempel vises et linjediagram, der sammenligner værdierne for Mobil og. Segmenter med organisk trafik anvendt på den forrige datatabel. Du kan vælge forskellige visualiseringer for at få forskellig indsigt i, hvilke personer der besøger dit website eller din app.

Registrering af afvigelser
Med registrering af afvigelser kan du identificere dataafvigelser ved hjælp af et linjediagram.
Du kan identificere dataafvigelser ved at bruge registrering af afvigelser i et linjediagram. Denne indstilling er som standard aktiveret i panelet Faneindstillinger, og du kan konfigurere registreringsmodellen ved hjælp af disse to indstillinger:
- Træningsperiode (sidste dage) refererer til det antal dage før det valgte datointerval, som bruges til at beregnede den forventede værdi af den viste metric i modellen til registrering af afvigelser.
- Hvis det aktuelt valgte datointerval eksempelvis er de første ti dage i måneden og du angiver en træningsperiode på syv dage, er det data fra de syv dage umiddelbart før månedens start, der bruges i modellen til registrering af afvigelser.
- Følsomhed bruges til at angive den grænseværdi for sandsynlighed, under hvilken der rapporteres dataafvigelser. Følsomheden har ingen betydning for, hvordan modellen fungerer, men bruges udelukkende til at angive, hvilken "etiket" dataene skal have. Modellen bruges til at forudsige sandsynligheden for, at et punkt forekommer ved en bestemt værdi, uden hensyntagen til følsomheden.
- Eksempelvis betyder en følsomhed på 5 %, at ethvert punkt, der forekommer med en sandsynlighed på under 5 %, betragtes som en afvigelse. En model med højere følsomhed kan derfor føre til rapportering af flere dataafvigelser.
Når modellen til registrering af afvigelser er defineret, anvendes der en bayesiansk tidsseriemodel på træningsdataene i værktøjet Udforskninger for at udarbejde en prognose for værdien for den metric, der vises i tidsserien.
Til sidst rapporteres datapunktet som en afvigelse i Udforskninger ved hjælp af en statistisk signifikanstest med p-værdier som grænseværdier i henhold til den valgte følsomhed.
Konfigurer udforskning i frit format
Konfigurer udforskning i frit format med disse muligheder:
| Generelle muligheder | Beskrivelse |
|---|---|
| Visualisering |
Skift mellem diagramtyper. |
| Segmentsammenligning | Anvend op til 4 segmenter i udforskningen. |
| Filter | Brug betingelser til at angive en begrænsning for, hvilke data der skal vises i udforskningen. Filterbetingelser anvendes ved hjælp af OG-logik. |
| Muligheder ifm. tabeller | |
| Pivot | Få segmenter vist som rækker eller kolonner i tabellen. |
| Rækker | Få op til fem dimensioner vist som rækker i tabellen. |
| Startrække | Vælg den første række i tabellen. |
| Vis rækker | Angiv det antal rækker, der skal vises i tabellen. |
| Kolonner | Få op til to dimensioner vist som kolonner i tabellen. Hvis du vælger flere dimensioner, oprettes der kolonnegrupper. |
| Startkolonnegruppe | Angiv startkolonnegruppen i tabellen. |
| Vis kolonnegrupper | Angiv det antal kolonnegrupper, der skal vises i tabellen. |
| Værdier | Få op til ti metrics vist i tabellen. |
| Celletype | Få metric-værdier vist som almindelig tekst, søjlediagrammer eller varmekort. |
| Muligheder ifm. cirkeldiagrammer | |
| Opdeling | Den dimension, der bruges opdeling af dataserierne i visualiseringen. |
| Rækkegrænse | Angiv det antal dataserier, der skal vises i visualiseringen. |
| Værdier | Få en enkelt metric vist i diagrammet. |
| Muligheder ifm. linjediagrammer | |
| Granularitet | Angiv datointervallet for diagrammet. Ugeintervallet starter med søndag. Månedsintervallet starter med den første dag i måneden. |
| Opdeling | Den dimension, der bruges opdeling af dataserierne i visualiseringen. |
| Linjer pr. dimension | Angiv det antal dataserier, der skal vises i visualiseringen. |
| Værdier | Få en enkelt metric vist i diagrammet. |
| Registrering af afvigelser | Slå registrering af afvigelser til eller fra. Du kan få flere oplysninger nedenfor. |
| Træningsperiode (sidste dage) | Forlæng eller forkort det tidsrum, inden for hvilket dine data skal undersøges. Længere træningsperioder kan øge nøjagtigheden. |
| Følsomhed | Angiv den grænseværdi for sandsynlighed, under hvilken der rapporteres dataafvigelser. En højere følsomhedsværdi kan medføre, at der rapporteres flere afvigelser. |
| Muligheder ifm. spredningsdiagrammer | |
| Opdeling | Den dimension, der bruges opdeling af dataserierne i visualiseringen. |
| Y-akse | Den metric, der anvendes på den lodrette akse. |
| X-akse | Den metric, der anvendes på den vandrette akse. |
| Muligheder ifm. geografiske kort | |
| Geografisk opdeling | Den placeringsdimension, der bruges til opdeling af dataserierne i visualiseringen. |
| Punkter pr. dimension | Angiv det antal datapunkter, der skal vises i visualiseringen. |
| Værdier | Få en enkelt metric vist i diagrammet. |