Guida di base sulla SEO per JavaScript
JavaScript è una parte importante della piattaforma web perché offre molte funzionalità che trasformano il web in una potente piattaforma applicativa. Rendere le tue applicazioni web basate su JavaScript rilevabili tramite la Ricerca Google può aiutarti a trovare nuovi utenti e a rinnovare il coinvolgimento di quelli esistenti, quando cercano i contenuti offerti dalle tue app web. Anche se la Ricerca Google esegue JavaScript con una versione sempre aggiornata di Chromium, puoi comunque ottimizzare alcuni elementi.
Questa guida descrive il modo in cui la Ricerca Google elabora JavaScript e le best practice per migliorare le app web JavaScript per la Ricerca Google.
In che modo Google elabora JavaScript
Googlebot elabora le app web JavaScript in tre fasi principali:
- Scansione
- Rendering
- Indicizzazione
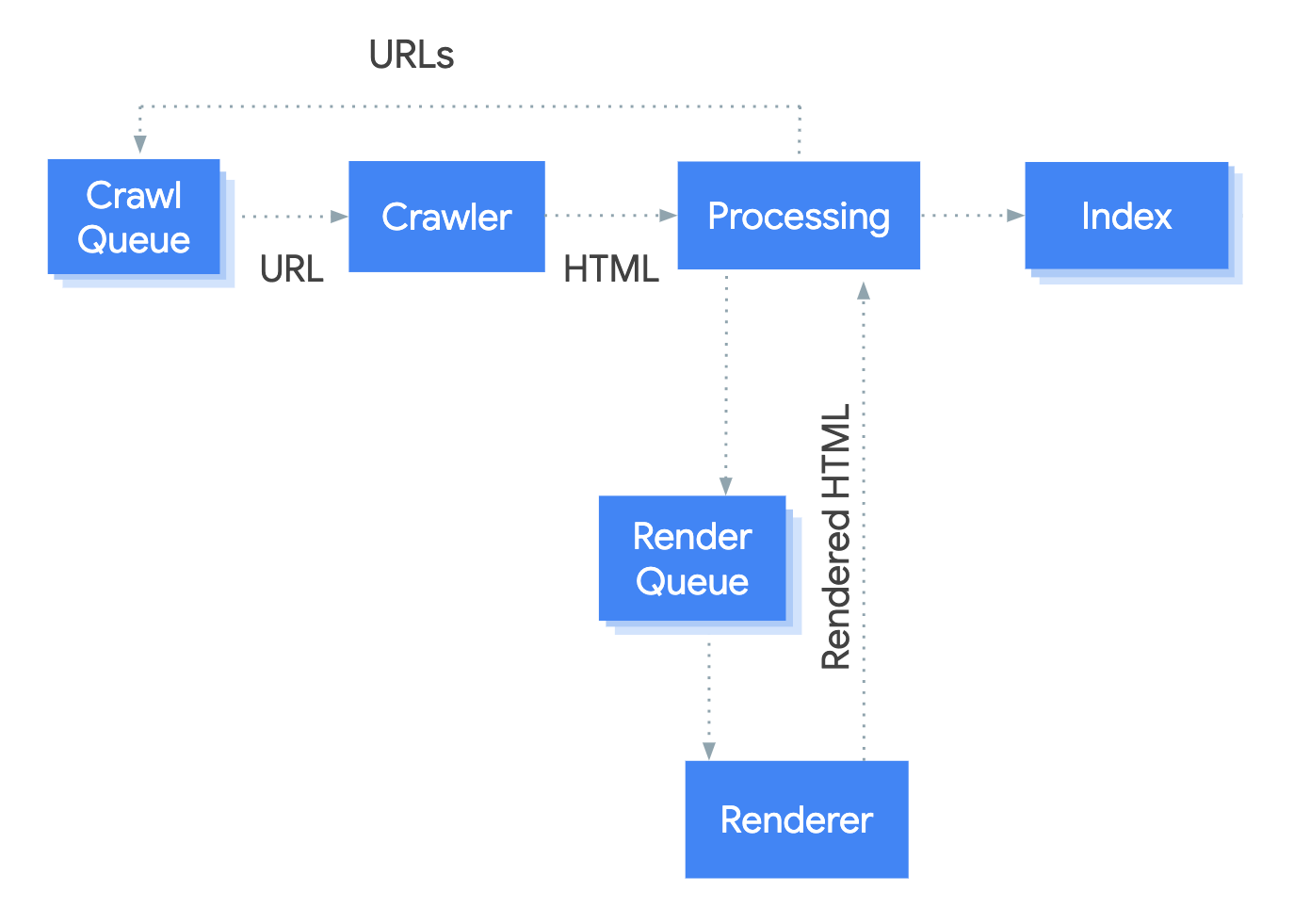
Googlebot mette in coda le pagine sia per la scansione che per il rendering. Non è immediatamente evidente quando una pagina è in attesa di scansione e quando è in attesa di rendering.
Quando Googlebot recupera un URL dalla coda di scansione tramite una richiesta HTTP, controlla innanzitutto se tu consenti la scansione leggendo il file robots.txt. Se nel file la scansione dell'URL è contrassegnata come non consentita, Googlebot salta la richiesta HTTP per questo URL e, di conseguenza, salta l'URL.
Googlebot analizza quindi la risposta per altri URL nell'attributo href dei link HTML e aggiunge gli URL alla coda di scansione. Per impedire il rilevamento del link, utilizza il meccanismo nofollow.
La scansione di un URL e l'analisi della risposta HTML funzionano bene per siti web classici o per pagine con rendering lato server, in cui l'HTML nella risposta HTTP include tutti i contenuti. Alcuni siti JavaScript potrebbero utilizzare il modello shell dell'app, in cui il codice HTML iniziale non include i contenuti effettivi, rendendo necessaria l'esecuzione di JavaScript da parte di Google prima che possa vedere i contenuti effettivi della pagina generati da JavaScript.
Google mette in coda tutte le pagine per il rendering, a meno che un meta tag o un'intestazione del file robots non indichino di non indicizzare una determinata pagina. La pagina potrebbe rimanere in questa coda per alcuni secondi o per un periodo più lungo. Quando le risorse di Google lo consentono, un'istanza di Chromium headless
esegue il rendering della pagina e il codice JavaScript. Googlebot analizza di nuovo i link delll'HTML di cui è stato eseguito il rendering
e aggiunge gli URL individuati alla coda di scansione. Google utilizza l'HTML di cui è stato eseguito il rendering anche per indicizzare la pagina.
Tieni presente che il rendering lato server o il pre-rendering sono comunque un'ottima soluzione, perché rendono il tuo sito web più veloce per utenti e crawler, e anche perché non tutti i bot possono eseguire JavaScript.
Descrivere la pagina con titoli e snippet univoci
Elementi <title> univoci e descrittivi e meta descrizioni utili aiutano gli utenti a identificare rapidamente il risultato migliore per il loro scopo. Scopri quali caratteristiche rendono efficaci gli elementi <title> e le meta descrizioni nelle nostre linee guida.
Puoi utilizzare JavaScript per impostare o modificare la meta descrizione e l'elemento <title>.
La Ricerca Google potrebbe mostrare un link del titolo diverso in base alla query dell'utente.
Questo si verifica quando il titolo o la descrizione hanno una pertinenza scarsa rispetto ai contenuti della pagina o quando
abbiamo trovato nella pagina alternative che corrispondono meglio alla query di ricerca. Scopri di più sul motivo per cui il titolo del risultato di ricerca potrebbe essere diverso dall'elemento <title> della pagina.
Scrivere codice compatibile
I browser offrono molte API, e JavaScript è un linguaggio in rapida evoluzione. Google presenta alcune limitazioni relative alle API e alle funzionalità JavaScript che supporta. Per assicurarti che il tuo codice sia compatibile con Google, segui le nostre linee guida per la risoluzione dei problemi relativi a JavaScript.
Ti consigliamo di utilizzare la pubblicazione differenziale e i polyfill se rilevi la mancanza di un'API browser di cui hai bisogno per una funzionalità. Poiché per alcune funzionalità del browser non è possibile eseguire il polyfill, ti consigliamo di consultare la documentazione relativa ai polyfill per conoscere le potenziali limitazioni.
Utilizzare codici di stato HTTP significativi
Googlebot utilizza i codici di stato HTTP per scoprire se si sono verificati dei problemi durante la scansione della pagina.
Per comunicare a Googlebot se una pagina non può essere sottoposta a scansione o indicizzazione, usa un codice di stato significativo, ad esempio il codice 404 per una pagina non trovata oppure il codice 401 per le pagine disponibili previo accesso. Puoi utilizzare i codici di stato HTTP per comunicare a Googlebot se una pagina è stata spostata
su un nuovo URL, in modo che l'indice possa essere aggiornato di conseguenza.
Ecco un elenco di codici di stato HTTP e i relativi effetti sulla Ricerca Google.
Evitare gli errori soft 404 nelle app a pagina singola
Nelle app a pagina singola con rendering lato client, il routing viene spesso implementato come routing lato client.
In questo caso, l'utilizzo di codici di stato HTTP significativi può essere impossibile o poco pratico.
Per evitare errori soft 404 quando utilizzi il rendering e il routing lato client, adotta una delle seguenti strategie:
- Usa un reindirizzamento JavaScript a un URL per cui il server risponde con un codice di stato HTTP
404(ad esempio/not-found). - Aggiungi un elemento
<meta name="robots" content="noindex">alle pagine di errore utilizzando JavaScript.
Di seguito è riportato un esempio di codice per l'approccio basato sul reindirizzamento:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
window.location.href = '/not-found'; // redirect to 404 page on the server.
}
})
Di seguito è riportato un esempio di codice per l'approccio basato sul tag noindex:
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
// Note: This example assumes there is no other robots meta tag present in the HTML.
const metaRobots = document.createElement('meta');
metaRobots.name = 'robots';
metaRobots.content = 'noindex';
document.head.appendChild(metaRobots);
}
})
Usare l'API History anziché i frammenti
Google può eseguire la scansione del tuo link solo se è un
elemento HTML <a> con un attributo href.
Per le applicazioni a pagina singola con routing lato client, usa l'API History per implementare il routing tra diverse visualizzazioni della tua app web. Per assicurarti che Googlebot possa analizzare ed estrarre i tuoi URL, evita di usare i frammenti per caricare contenuti diversi della pagina. Il seguente esempio costituisce una prassi scorretta, perché Googlebot non può risolvere in modo affidabile gli URL:
<nav>
<ul>
<li><a href="#/products">Our products</a></li>
<li><a href="#/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</p>
</div>
<script>
window.addEventListener('hashchange', function goToPage() {
// this function loads different content based on the current URL fragment
const pageToLoad = window.location.hash.slice(1); // URL fragment
document.getElementById('placeholder').innerHTML = load(pageToLoad);
});
</script>
Puoi invece assicurarti che i tuoi URL dei link siano accessibili a Googlebot implementando l'API History:
<nav>
<ul>
<li><a href="/products">Our products</a></li>
<li><a href="/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</p>
</div>
<script>
function goToPage(event) {
event.preventDefault(); // stop the browser from navigating to the destination URL.
const hrefUrl = event.target.getAttribute('href');
const pageToLoad = hrefUrl.slice(1); // remove the leading slash
document.getElementById('placeholder').innerHTML = load(pageToLoad);
window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history.
}
// Enable client-side routing for all links on the page
document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage));
</script>
Inserire correttamente il tag link rel="canonical"
Anche se sconsigliamo di utilizzare JavaScript per questa operazione, è possibile inserire un tag link rel="canonical" con JavaScript.
La Ricerca Google rileverà l'URL canonico inserito quando esegue il rendering della pagina.
Ecco un esempio per inserire un tag link rel="canonical" con JavaScript:
fetch('/api/cats/' + id)
.then(function (response) { return response.json(); })
.then(function (cat) {
// creates a canonical link tag and dynamically builds the URL
// e.g. https://example.com/cats/simba
const linkTag = document.createElement('link');
linkTag.setAttribute('rel', 'canonical');
linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName;
document.head.appendChild(linkTag);
});
Utilizzare meta tag robots con attenzione
Puoi impedire a Google di indicizzare una pagina o di seguire link tramite il meta tag robots.
Ad esempio, se aggiungi il seguente meta tag nella parte superiore della pagina, impedisci a Google di indicizzarla:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Puoi utilizzare JavaScript per aggiungere un meta tag robots a una pagina o modificarne i contenuti. Nel codice di esempio che segue viene
mostrato come cambiare il meta tag robots con JavaScript per impedire l'indicizzazione della pagina corrente se
una chiamata API non restituisce contenuti.
fetch('/api/products/' + productId)
.then(function (response) { return response.json(); })
.then(function (apiResponse) {
if (apiResponse.isError) {
// get the robots meta tag
var metaRobots = document.querySelector('meta[name="robots"]');
// if there was no robots meta tag, add one
if (!metaRobots) {
metaRobots = document.createElement('meta');
metaRobots.setAttribute('name', 'robots');
document.head.appendChild(metaRobots);
}
// tell Google to exclude this page from the index
metaRobots.setAttribute('content', 'noindex');
// display an error message to the user
errorMsg.textContent = 'This product is no longer available';
return;
}
// display product information
// ...
});
Se Google rileva noindex nel meta tag robots prima di eseguire il codice JavaScript,
non esegue il rendering o l'indicizzazione della pagina.
Utilizzare la memorizzazione nella cache di lunga durata
Googlebot memorizza i contenuti nella cache in modo massiccio per ridurre le richieste di rete e l'utilizzo delle risorse. WRS potrebbe ignorare le intestazioni di memorizzazione nella cache. Questo potrebbe portare WRS a utilizzare risorse JavaScript o CSS obsolete. Il fingerprinting dei contenuti consente di evitare questo problema inserendo un'impronta dei contenuti nel nome file, ad esempio main.2bb85551.js.
L'impronta dipende dai contenuti del file, quindi gli aggiornamenti generano ogni volta un nome file diverso. Per saperne di più, consulta la guida web.dev sulle strategie di memorizzazione nella cache di lunga durata.
Utilizzare dati strutturati
Quando utilizzi dati strutturati nelle tue pagine, puoi usare JavaScript per generare il codice JSON-LD richiesto e inserirlo nella pagina. Assicurati di testare l'implementazione in modo da evitare problemi.
Seguire le best practice relative ai componenti web
Google supporta i componenti web. Quando Google esegue il rendering di una pagina, unisce i contenuti shadow DOM e light DOM. Ciò significa che può vedere solo i contenuti visibili nel codice HTML sottoposto a rendering. Per assicurarti che Google possa ancora vedere i tuoi contenuti dopo il rendering, utilizza il Test dei risultati avanzati o lo strumento Controllo URL ed esamina il codice HTML sottoposto a rendering.
Se i contenuti non sono visibili nell'HTML sottoposto a rendering, Google non potrà indicizzarli.
L'esempio riportato di seguito crea un componente web che mostra i contenuti light DOM all'interno del relativo shadow DOM. Un modo per assicurarti che i contenuti light DOM e shadow DOM siano mostrati nel codice HTML sottoposto a rendering consiste nell'utilizzare un elemento Slot.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Dopo il rendering, Google è in grado di indicizzare questi contenuti:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Correggere le immagini e i contenuti con caricamento lento
Le immagini possono incidere notevolmente sulla larghezza di banda e sulle prestazioni. Una soluzione efficace consiste nell'uso del caricamento lento, che consente di caricare le immagini solo quando l'utente sta per visualizzarle. Per assicurarti di implementare il caricamento lento in modo ottimizzato per la ricerca, segui le nostre linee guida per il caricamento lento.
Progettazione ai fini di una migliore accessibilità
Crea le pagine per gli utenti, non soltanto per i motori di ricerca. Quando progetti il tuo sito, pensa alle esigenze degli utenti, compresi coloro che potrebbero non utilizzare un browser che supporta JavaScript (ad esempio, chi fa uso di screen reader o di dispositivi mobili meno avanzati). Uno dei modi più facili per verificare l'accessibilità del tuo sito è visualizzarlo in anteprima nel browser con JavaScript disattivato oppure in un browser di solo testo come Lynx. La visualizzazione di un sito come solo testo può aiutarti inoltre a identificare altri contenuti difficilmente rilevabili da Google, ad esempio il testo incorporato nelle immagini.