자바스크립트 검색엔진 최적화의 기본사항 이해하기
JavaScript는 웹을 강력한 애플리케이션 플랫폼으로 만드는 여러 기능을 제공한다는 점에서 웹 플랫폼의 중요한 부분을 차지합니다. JavaScript 기반의 웹 애플리케이션이 Google 검색에서 개선되도록 만들면 사용자가 웹 앱에서 제공하는 콘텐츠를 검색할 수 있으므로 신규 사용자를 발굴하고 기존 사용자의 재참여를 유도할 수 있습니다. Google 검색은 Chromium의 Evergreen 버전을 사용하여 JavaScript를 실행하지만, 몇 가지 부분을 최적화할 수 있습니다.
이 가이드에서는 Google 검색이 JavaScript를 처리하는 방법과 JavaScript 웹 앱을 Google 검색에 최적화하기 위한 권장사항을 설명합니다.
Google에서 자바스크립트를 처리하는 방식
Google은 다음 세 가지 주요 단계로 자바스크립트 웹 앱을 처리합니다.
- 크롤링
- 렌더링
- 색인 생성
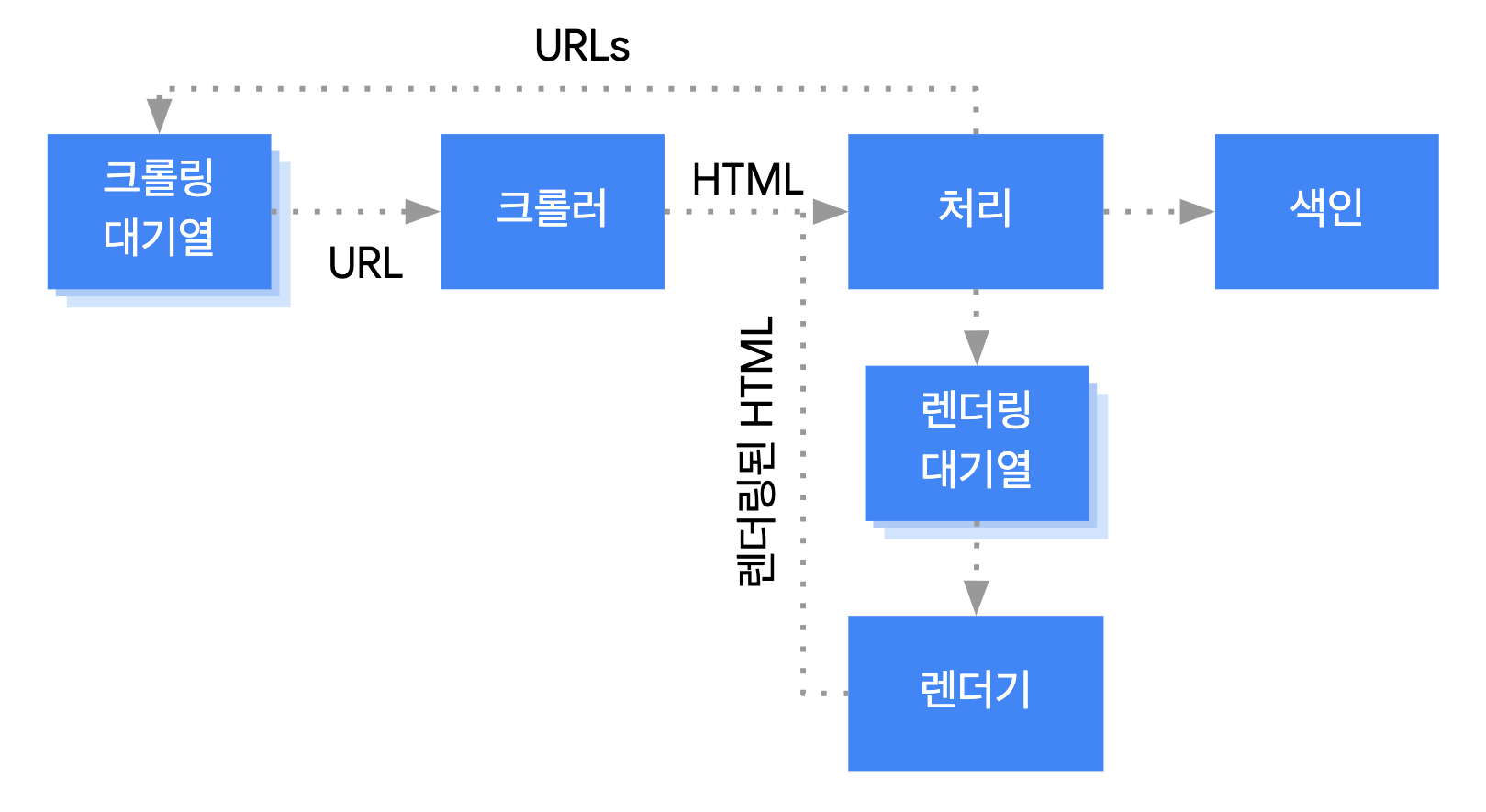
Googlebot은 페이지를 크롤링 및 렌더링 대기열에 추가하며, 페이지가 크롤링 및 렌더링을 기다리고 있는 경우 바로 확인할 방법은 없습니다.
Google이 HTTP 요청을 전송하여 크롤링 대기열에서 URL을 가져올 때는 크롤링이 허용되는지 먼저 확인합니다. Googlebot이 robots.txt 파일을 읽고 URL이 허용되어 있지 않으면 이 URL에 관한 HTTP 요청과 URL 자체를 건너뜁니다.
그런 다음 Googlebot은 HTML 링크의 href 속성에 있는 다른 URL에 관한 응답을
파싱하고 크롤링 대기열에 이러한 URL을 추가합니다. 링크가 검색되지 않도록 하려면
nofollow 메커니즘을 사용하세요.
URL 크롤링 및 HTML 응답 파싱은 HTTP 응답의 HTML에 모든 콘텐츠가 포함되어 있는 기존 방식의 웹사이트 또는 서버 측 렌더링 페이지에서 원활하게 작동합니다. 일부 JavaScript 사이트에서는 초기 HTML에 실제 콘텐츠가 포함되어 있지 않으며 Google이 JavaScript에서 생성되는 실제 페이지 콘텐츠를 보기 위해 JavaScript를 실행해야 하는 앱 셸 모드를 사용하기도 합니다.
robots meta 태그 또는 헤더에 Google에 페이지의 색인을 생성하지 말라고 명시되어 있지 않은 한 Googlebot은 모든 페이지를 렌더링 대기열에 추가합니다. 페이지는 몇 초 동안 이 대기열에 머무를 수 있지만, 그보다 오래 있을 수는 없습니다. Google의 리소스가 허용되면 헤드리스 Chromium이 페이지를 렌더링하고 JavaScript를 실행합니다. Googlebot은 렌더링된 링크의 HTML을 다시 파싱하고 발견된 URL을 크롤링 대기열에 추가합니다. Google은 또한 렌더링된 HTML을 사용하여 페이지의 색인을 생성합니다.
서버 측 또는 사전 렌더링은 사용자와 크롤러가 웹사이트를 더욱 신속하게 로드할 수 있게 만들고 모든 봇이 JavaScript를 실행할 수 없다는 점에서 여전히 좋은 방법입니다.
고유한 제목과 스니펫을 사용하여 페이지 설명하기
고유하고 구체적인 <title> 요소와 유용한 메타 설명을 작성하면 사용자가 목표에 가장 부합하는 결과를
빠르게 찾을 수 있습니다. 가이드라인에서 효과적인 <title> 요소와 메타 설명의 조건을 알아보세요.
자바스크립트를 사용하여 메타 설명과 <title> 요소를 설정하거나 변경할 수 있습니다.
Google 검색은 사용자의 검색어에 따라 다른 제목 링크를 표시할 수 있습니다.
이러한 상황은 제목이나 설명이 페이지 콘텐츠와 관련성이 낮거나 Google 검색이 페이지에서 검색어와 더 일치도가 높은 결과를 발견하는 경우 발생합니다. 검색결과 제목이 페이지의 <title> 요소와 다르게 표시될 수 있는 이유를 자세히 알아보세요.
호환되는 코드 작성하기
브라우저에서는 여러 API를 제공하며 자바스크립트는 빠르게 진화하는 언어입니다. 따라서 Google이 지원하는 API 및 JavaScript 기능은 일부 제한되어 있습니다. 코드가 Google과 호환되는지 확인하려면 JavaScript 문제 해결 가이드라인을 참고하세요.
기능 감지를 통해 필요한 브라우저 API가 누락된 것을 발견했다면 차등 게재 및 폴리필을 사용하는 것이 좋습니다. 일부 브라우저 기능은 폴리필할 수 없으므로 폴리필 설명서에서 가능한 제한사항을 확인하는 것이 좋습니다.
의미 있는 HTTP 상태 코드 사용하기
Googlebot은 HTTP 상태 코드를 사용하여 페이지를 크롤링할 때 문제가 있었는지 확인합니다.
페이지 크롤링 또는 색인 생성이 불가능하다고 Googlebot에 알리려면 의미 있는 상태 코드를 사용하세요. 찾을 수 없는 페이지에는 404 코드를, 로그인이 필요한 페이지에는 401 코드를 사용하면 됩니다. 페이지가 새로운 URL로 이동된 경우 HTTP 상태 코드로 Googlebot에 알려 색인이 정확하게 업데이트되도록 할 수 있습니다.
HTTP 상태 코드 목록과 상태 코드가 Google 검색에 미치는 영향은 다음과 같습니다.
단일 페이지 앱에서 soft 404 오류 방지하기
클라이언트 측에서 렌더링된 단일 페이지 앱에서 라우팅이 클라이언트 측 라우팅으로 구현되는 경우가 많습니다.
이 경우 의미 있는 HTTP 상태 코드를 사용하는 것이 불가능하거나 비효율적일 수 있습니다.
클라이언트 측 렌더링 및 라우팅을 사용할 때 soft 404오류를 방지하려면 다음 전략 중 하나를 사용하세요.
- 서버가
404HTTP 상태 코드로 응답하는 경우 URL에 자바스크립트 리디렉션을 사용합니다(예:/not-found). - 자바스크립트를 사용하여 오류 페이지에
<meta name="robots" content="noindex">를 추가합니다.
다음은 리디렉션 접근방식 관련 샘플 코드입니다.
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
window.location.href = '/not-found'; // redirect to 404 page on the server.
}
})
다음은 noindex 태그 접근방식 관련 샘플 코드입니다.
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
// Note: This example assumes there is no other robots meta tag present in the HTML.
const metaRobots = document.createElement('meta');
metaRobots.name = 'robots';
metaRobots.content = 'noindex';
document.head.appendChild(metaRobots);
}
})
프래그먼트 대신 History API 사용
Google에서는 href 속성이 있는 <a> HTML 요소인 경우에만 링크를 크롤링할 수 있습니다.
클라이언트 측 라우팅 방식을 사용하는 단일 페이지 애플리케이션의 경우 History API를 사용하여 웹 앱의 다양한 보기 간 라우팅을 구현합니다. Googlebot이 URL을 파싱하고 추출하도록 하려면 다양한 페이지 콘텐츠 로드 시 프래그먼트를 사용하지 마세요. 다음은 Googlebot이 URL을 안정적으로 연결할 수 없으므로 좋지 않은 사례입니다.
<nav>
<ul>
<li><a href="#/products">Our products</a></li>
<li><a href="#/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</p>
</div>
<script>
window.addEventListener('hashchange', function goToPage() {
// this function loads different content based on the current URL fragment
const pageToLoad = window.location.hash.slice(1); // URL fragment
document.getElementById('placeholder').innerHTML = load(pageToLoad);
});
</script>
대신 History API를 구현하여 URL에 Googlebot이 액세스하도록 하면 됩니다.
<nav>
<ul>
<li><a href="/products">Our products</a></li>
<li><a href="/services">Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id="placeholder">
<p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</p>
</div>
<script>
function goToPage(event) {
event.preventDefault(); // stop the browser from navigating to the destination URL.
const hrefUrl = event.target.getAttribute('href');
const pageToLoad = hrefUrl.slice(1); // remove the leading slash
document.getElementById('placeholder').innerHTML = load(pageToLoad);
window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history.
}
// Enable client-side routing for all links on the page
document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage));
</script>
rel="canonical" 링크 태그를 올바르게 삽입하기
이를 위해 자바스크립트를 사용하지 않는 것이 좋지만 자바스크립트로 rel="canonical" 링크 태그를 삽입할 수는 있습니다.
Google 검색은 페이지를 렌더링할 때 삽입된 표준 URL을 가져올 수 있습니다.
다음은 자바스크립트로 rel="canonical" 링크 태그를 삽입하는 예입니다.
fetch('/api/cats/' + id)
.then(function (response) { return response.json(); })
.then(function (cat) {
// creates a canonical link tag and dynamically builds the URL
// e.g. https://example.com/cats/simba
const linkTag = document.createElement('link');
linkTag.setAttribute('rel', 'canonical');
linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName;
document.head.appendChild(linkTag);
});
robots meta 태그 신중하게 사용하기
robots meta 태그를 통해 Google이 페이지의 색인을 생성하거나 링크를 따라가지 못하게 할 수 있습니다.
예를 들어 페이지 상단에 다음 meta 태그를 추가하면 Google이 페이지의 색인을 생성하지 않습니다.
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
자바스크립트를 사용하여 페이지에 robots meta 태그를 추가하거나 콘텐츠를 변경할 수 있습니다. 다음 예제 코드는 API 호출이 콘텐츠를 반환하지 않는 경우 현재 페이지의 색인이 생성되지 않도록 JavaScript로 robots meta 태그를 변경하는 방법을 보여 줍니다.
fetch('/api/products/' + productId)
.then(function (response) { return response.json(); })
.then(function (apiResponse) {
if (apiResponse.isError) {
// get the robots meta tag
var metaRobots = document.querySelector('meta[name="robots"]');
// if there was no robots meta tag, add one
if (!metaRobots) {
metaRobots = document.createElement('meta');
metaRobots.setAttribute('name', 'robots');
document.head.appendChild(metaRobots);
}
// tell Google to exclude this page from the index
metaRobots.setAttribute('content', 'noindex');
// display an error message to the user
errorMsg.textContent = 'This product is no longer available';
return;
}
// display product information
// ...
});
Google이 JavaScript를 실행하기 전에 robots meta 태그에서 noindex를 발견하면 페이지를 렌더링하거나 페이지 색인을 생성하지 않습니다.
장기간 유지되는 캐싱 사용하기
Googlebot은 네트워크 요청 및 리소스 사용을 줄이기 위해 적극적으로 캐싱을 실행합니다. WRS는 캐싱 헤더를 무시할 수 있으며, 이로 인해 WRS에서 오래된 JavaScript 또는 CSS 리소스를 사용할 수 있습니다. 콘텐츠 지문 수집은 main.2bb85551.js와 같이 콘텐츠의 지문을 파일 이름의 일부로 만들어 이 문제를 방지합니다.
지문은 파일의 콘텐츠에 따라 달라지므로 업데이트할 때마다 다른 파일 이름이 생성됩니다. 자세한 내용은 오래 지속되는 캐싱 전략에 관한 web.dev 가이드를 참조하세요.
구조화된 데이터 사용하기
페이지에서 구조화된 데이터를 사용할 때 JavaScript를 사용해 필수 JSON-LD를 생성하고 페이지에 삽입할 수 있습니다. 문제를 방지하기 위해 구현을 테스트하는 것을 잊지 마세요.
웹 구성요소 권장사항 따르기
Google에서는 웹 구성요소를 지원합니다. Google은 페이지를 렌더링할 때 shadow DOM 및 light DOM 콘텐츠를 평면화합니다. 즉, Google은 렌더링된 HTML에 표시되는 콘텐츠만 볼 수 있습니다. Google이 렌더링된 후에도 콘텐츠를 볼 수 있는지 확인하려면 리치 결과 테스트 또는 URL 검사 도구를 사용하여 렌더링된 HTML을 살펴 보세요.
콘텐츠가 렌더링된 HTML에 표시되지 않으면 Google이 색인을 생성할 수 없습니다.
다음 예는 shadow DOM 내의 light DOM 콘텐츠를 표시하는 웹 구성요소를 생성합니다. light DOM 및 shadow DOM 콘텐츠가 모두 렌더링된 HTML에 표시되는지 확인하기 위한 한 가지 방법은 Slot 요소를 사용하는 것입니다.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
렌더링된 후에 Google은 이 콘텐츠의 색인을 생성합니다.
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
이미지 및 지연 로드 콘텐츠 문제 해결
이미지는 상당히 큰 대역폭과 성능을 요구할 수 있습니다. 지연 로드를 사용하여 사용자가 이미지를 보려고 할 때만 이미지를 로드하는 것이 좋습니다. 검색에 적합한 방법으로 지연 로드를 구현하려면 Google의 지연 로드 가이드라인을 따르세요.
접근성을 고려한 사이트 설계
검색엔진뿐 아니라 사용자를 고려한 페이지를 만듭니다. 사이트를 설계할 때는 JavaScript가 지원되지 않을 가능성이 있는 브라우저를 사용하는 경우(예: 스크린 리더나 구형 휴대기기 사용자)를 포함하여 사용자의 요구사항을 고려해야 합니다. 사이트의 접근성을 테스트하는 가장 쉬운 방법 중 하나는 브라우저에서 JavaScript 기능을 중지하고 사이트를 미리 보거나 Lynx와 같은 텍스트 전용 브라우저를 사용하여 사이트를 확인하는 것입니다. 또한 텍스트 전용으로 사이트를 보면 이미지에 삽입된 텍스트처럼 Google이 보기 힘든 기타 콘텐츠를 찾을 수 있습니다.