如果 Google 搜索结果中显示没有某个网页的信息,如下所示:
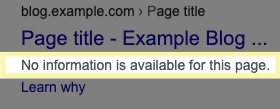
这意味着该网站阻止了 Google 创建网页说明,但实际上并未向 Google 隐藏该网页。
如果您是此网站的所有者,可以让 Google 读取该网页以创建良好的说明,或者完全从 Google 搜索结果中隐藏该网页,从而改善此搜索结果。若要了解具体方法,请阅读下文。
如何解决问题
这不是我的网站
网页所有者禁止 Google 读取该网页,这会导致我们无法创建网页说明。遗憾的是,Google 也无能为力。
如果您认识该网站的所有者,请告知他们,并向他们发送指向此网页的链接。
这是我的网站
如果您是这条被屏蔽的结果所在网站的所有者,可能会出于以下原因而看到这条结果:
该网页被 robots.txt 屏蔽了
说明
您网站的 robots.txt 文件* 中有规则会阻止 Google 读取该网页。Google 必须读取相应网页才能生成说明以显示在搜索结果中。如果 Google 获准显示相应网页,不过无法读取该网页,则会显示该网页但无说明信息。
*robots.txt 文件是一种标准文件,网站可使用该文件阻止搜索引擎抓取其中的特定网页。某些网站托管服务会自动为其客户创建此文件。下一部分将介绍如何确认这是不是问题所在。
1. 确认问题
2. 解决问题
如需解决此问题,请采取下列措施之一:
措施 1:允许 Google 读取您的网页
如果您想在 Google 搜索结果中显示适当的网页说明,则必须修复您的 robots.txt 文件以允许 Google 读取该网页。
选项 2:从 Google 搜索结果中完全屏蔽相应网页
若要完全阻止网页显示在 Google 搜索结果中,请按以下步骤操作:
- 执行下列操作之一,以屏蔽您的网页:
- 从您的网站中移除该网页,或
- 要求用户登录才能访问该网页,或
- 在您的网页上使用“noindex”。如果使用 noindex,您还必须移除会阻止搜索引擎访问该网页的 robots.txt 规则。听起来很奇怪,但 Google 需要能够读取该网页,才能看到“noindex”指令。您可在此处了解 robots.txt。
- 使用“移除过期内容”工具将更改告知 Google。此操作将从搜索结果中快速移除该网页的所有已存储副本。将搜索结果中的网址复制到该工具中。