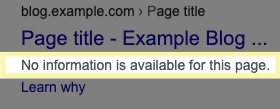
תיאור
קובץ Robots.txt* של האתר שלכם מכיל כלל שמונע מ-Google לקרוא את הדף. Google חייבת לקרוא דף כדי ליצור תיאור שיופיע בתוצאות החיפוש. אם Google מורשית להציג את הדף אבל לא יכולה לקרוא אותו, הדף יוצג ב-Google ללא תיאור.
*קובץ Robots.txt הוא קובץ סטנדרטי שבו אתרים משתמשים כדי למנוע ממנועי חיפוש לסרוק דפים ספציפיים באתרים. חלק מהשירותים לאירוח אתרים יוצרים את הקובץ הזה ללקוחות שלהם באופן אוטומטי. בקטע הבא מוסבר איך מוודאים שזו הבעיה.
1. מוודאים שזו הבעיה
מוודאים שהדף נחסם על ידי קובץ robots.txt באתר.
2. פותרים את הבעיה
כדי לפתור את הבעיה הזו, אתם יכולים לבצע אחת מהפעולות הבאות:
אפשרות 1: מאפשרים ל-Google לקרוא את הדף
כדי שיופיע תיאור מתאים של דף בחיפוש Google, צריך לתקן את קובץ robots.txt וכך לאפשר ל-Google לקרוא את הדף.
אפשרות 2: חוסמים את הדף לגמרי מתוצאות החיפוש ב-Google
אפשר למנוע לגמרי את הצגת הדף בתוצאות החיפוש ב-Google. לשם כך, פועלים לפי השלבים הבאים:
- מבצעים אחת מהפעולות הבאות כדי לחסום את הדף:
- מסירים את הדף מהאתר, או
- דורשים מהמשתמשים להזין פרטי כניסה כדי לגשת לדף, או
- משתמשים בתג noindex בדף. אם משתמשים בתג noindex, צריך גם להסיר מקובץ robots.txt את הכלל שחוסם את הדף בפני מנועי חיפוש. אולי זה נשמע מוזר, אבל Google צריכה לקרוא את הדף כדי לראות את הוראת noindex. מידע נוסף על קובצי robots.txt
- מודיעים ל-Google על השינוי באמצעות הכלי להסרת תוכן מיושן. הפעולה הזו תסיר במהירות את כל העותקים המאוחסנים של הדף מתוצאות החיפוש. מעתיקים את כתובת ה-URL מתוצאות החיפוש אל הכלי.