Google の検索エンジンの仕組み、検索結果と掲載順位について
Google 検索は完全に自動化された検索エンジンです。「ウェブ クローラー」という種類のソフトウェアを使用して定期的にウェブを探索し、見つけたページを Google のインデックスに登録しています。Google 検索結果に表示されるページのほとんどは、手動でインデックス登録されたものではなく、ウェブクローラがウェブをクロールして見つけ、自動的に追加したものです。ここでは、ウェブサイトの所有者の目線で、Google 検索の仕組みについて説明します。このドキュメントで解説する基本的な知識があれば、クロールに関する問題を解決し、ページがインデックスに登録され、Google 検索結果にサイトが表示されるように最適化できます。

開始するにあたっての注意事項
Google 検索の仕組みについて詳しく見ていく前に注意していただきたい点があります。それは、Google がサイトをクロールする頻度やサイトの掲載順位を上げたりするために金銭を受け取ることはない、ということです。これと反する内容を耳にしたとしても、それは事実ではありませんのでご注意ください。
ページが Google 検索の基本事項に準拠していても、ページがクロールされてインデックスに登録され、検索結果に表示される保証はありません。
Google 検索の 3 つのステージの流れ
Google 検索には 3 つのステージがあります(すべてのページが各ステージを通るわけではありません)。
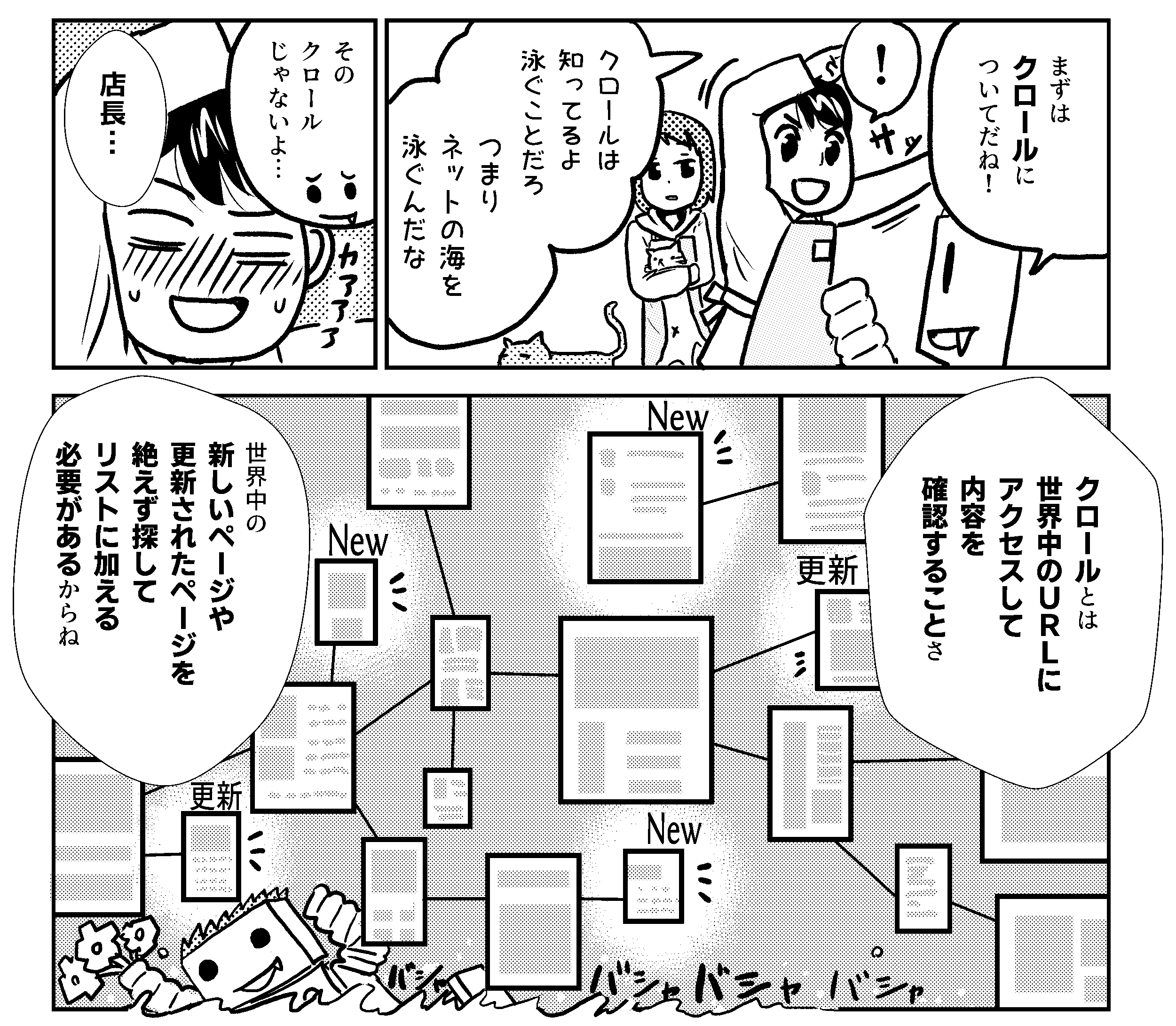
- クロール: Google は、クローラーと呼ばれる自動プログラムを使用して、ウェブ上で見つけたページからテキスト、画像、動画をダウンロードします。
- インデックス登録: Google は、見つけたページ上のテキスト、画像、動画ファイルを解析し、その情報を Google インデックス(大規模なデータベース)に保存します。
- 検索結果の表示: ユーザーが Google で検索すると、Google はユーザーの検索語句に関連する情報を返します。
クロール
最初のステージは、ウェブにどのようなページが存在するかを把握することです。すべてのウェブページを含むデータベースが存在する訳ではないため、Google は新しいページや更新されたページを絶えず検出し、既知のページリストに加える必要があります。このプロセスを「URL 検出」と読んでいます。Google がすでにアクセスしたことのあるページは、既知のページとなります。新しいページは、既知のページからリンクをたどることで検出されます。たとえば、カテゴリページなどのハブページの新しいブログ投稿へのリンクなどです。また、Google によるクロールを希望するページのリスト(サイトマップ)を提出することで、検出されるページもあります。

Google がページの URL を検出すると、そのページにアクセス(クロール)して内容を確認します。Google では、大規模なコンピュータ群を使用して、ウェブ上の数十億のページをクロールしています。この取得プログラムは Googlebot と呼ばれています(クローラー、ロボット、ボット、スパイダーとも呼ばれます)。Googlebot は、アルゴリズム処理を使用して、クロールするサイト、クロールする頻度、各サイトから取得するページ数を決定します。また、過負荷にならないように、Google のクローラーは、サイトのクロールが速くなりすぎないようにプログラムされています。このメカニズムは、サイトの応答(たとえば、HTTP 500 エラーは「スローダウン」を意味する)に基づいています。
ただし、Googlebot は検出したページをすべてクロールするわけではありません。一部のページはサイト所有者によってクロールが禁止されている場合がありますし、サイトにログインしないとアクセスできないページもあります。
Google はクロール中、ユーザーがアクセスしたページをブラウザがレンダリングするのと同じように、Chrome の最新版を使用してページをレンダリングし、検出した JavaScript を実行します。ウェブサイトはコンテンツをページに表示するために JavaScript を使用することが多く、レンダリングを行わないと Google はそのコンテンツを確認できないため、レンダリングは非常に重要です。

クロールの対象になるかどうかは、Google のクローラーがサイトにアクセスできるかどうかによって決まります。Googlebot のサイトアクセスに関する一般的な問題には、次のようなものがあります。
インデックス登録
ページがクロールされると、Google はそのページの内容を把握しようとします。このステージはインデックス登録と呼ばれ、<title> 要素や alt 属性など、テキスト コンテンツや主要なコンテンツのタグや属性、そして画像や動画などを処理して分析する作業が含まれます。

インデックス登録を行う際、Google はページがウェブ上の別のページの重複ページであるか、または正規ページであるかを判断します。正規ページは、検索結果に表示される可能性のあるページです。正規ページを選択するには、まず、インターネット上で見つけた同様のコンテンツを含むページをグループ化し(クラスタリングとも呼ばれます)、次にそのグループを代表するページを選択します(正規化)。グループ内の他のページは、ユーザーがモバイル デバイスから検索している場合や、グループ内の特定のページを探している場合など、異なるコンテキストで表示される可能性のある代替バージョンとして判断されます。
また、Google は正規ページとそのコンテンツに関するシグナルも収集します。こうした情報は、Google が検索結果にページを表示する次のステージで使用されます。シグナルの例としては、ページの言語、コンテンツの配信元の国、ページの使いやすさなどが挙げられます。
正規ページとそのグループについて収集された情報は、Google インデックスに保存されます。Google インデックスは、何千台ものコンピュータでホストされている大規模なデータベースです。ただし、インデックス登録は保証されているわけではなく、Google が処理するページのすべてがインデックスに登録されるとは限りません。

インデックスに登録されるかどうかは、ページのコンテンツとメタデータによっても左右されます。インデックス登録に関する一般的な問題としては、次のようなものがあります。
検索結果への表示
ユーザーが検索語句を入力すると、インデックスで一致するページが検索され、関連性が高く高品質であると判断された検索結果が返されます。関連性は、ユーザーの所在地、言語、デバイス(パソコンまたはスマートフォン)などの情報を含め、数多くの要素によって決まります。たとえば「自転車修理店」を検索した場合、パリのユーザーと香港のユーザーには異なる検索結果が表示されます。
ユーザーの検索語句によって検索結果ページに表示される検索結果の機能も変化します。たとえば、「自転車修理店」を検索すると、高い確率でローカル検索結果が表示され、画像検索結果は表示されません。ただし、「最新の自転車」を検索すると、ローカル検索結果は表示されずに画像検索結果が表示される可能性が高くなります。視覚要素ギャラリーで Google ウェブ検索の最も一般的な UI 要素をご確認いただけます。

ページがインデックスに登録されていることが Search Console に表示されているにもかかわらず、検索結果にそのページが表示されない場合があります。その場合、以下のような原因が考えられます。

このガイドでは Google 検索の仕組みについて説明していますが、Google では常にアルゴリズムの改善に努めています。改善内容については、Google 検索セントラル ブログをフォローして、随時情報をご確認ください。