BigQuery ist das vollständig verwaltete, kostengünstige Data Warehouse für Analysen im Petabyte-Bereich von Google. Mit dem BigQuery-Connector von Looker Studio können Sie in Looker Studio auf Daten aus Ihren BigQuery-Tabellen zugreifen.
Hinweise
Damit Sie in Looker Studio auf BigQuery-Daten zugreifen können, müssen Sie ein Google Cloud Billing-Konto angeben. BigQuery ist ein kostenpflichtiges Produkt. Beim Zugriff auf BigQuery über Looker Studio fallen daher eventuell Nutzungskosten an. Weitere Informationen zu den BigQuery-Preisen
Mit BigQuery verbinden
Looker Studio lässt sich mit einer Tabelle, einer Datenansicht oder einer benutzerdefinierten Abfrage in Google BigQuery verbinden.
Verbindung herstellen
Klicken Sie auf Erstellen und wählen Sie dann Bericht aus.
Der Berichtseditor wird eingeblendet und der Bereich Daten zum Bericht hinzufügen geöffnet.
Wenn Sie eine eingebettete Datenquelle erstellen möchten, wählen Sie den BigQuery-Connector aus.
- Sie können auch eine vorhandene wiederverwendbare Datenquelle auswählen. Klicken Sie dazu auf den Tab Meine Datenquellen und wählen Sie eine Datenquelle eines beliebigen Typs aus, die Sie zuvor erstellt haben oder die für Sie freigegeben wurde.
Konfigurieren Sie die Verbindung der Datenquelle mit Ihren BigQuery-Daten. Sie können eine Verbindung mit einer BigQuery-Tabelle oder ‑Datenansicht oder mit einer benutzerdefinierten SQL-Abfrage herstellen.
Klicken Sie auf Hinzufügen.
Daraufhin wird auf dem Berichtcanvas eine Tabelle angezeigt, die mit der Datenquelle verknüpft ist.
Eingebettete und wiederverwendbare Datenquellen im Vergleich
Datenquellen sind entweder eingebettet oder wiederverwendbar. Beide Typen können in Berichten enthalten sein.
Wenn Sie eine Datenquelle erstellen, während Sie an einem Bericht arbeiten, wird sie in den Bericht eingebettet. Sie können sie dann innerhalb des Berichts bearbeiten. Mit eingebetteten Datenquellen wird die Zusammenarbeit an Berichten und Datenquellen erleichtert. Jeder, der den Bericht bearbeiten darf, kann auch die Datenquelle bearbeiten und die Verbindungseinstellung ändern. Wenn Sie den Bericht freigeben oder kopieren, werden auch alle darin eingebetteten Datenquellen freigegeben bzw. kopiert.
Datenquellen, die Sie auf der Startseite erstellen, sind wiederverwendbar. Das heißt, sie lassen sich in verschiedenen Berichten nutzen. Mit wiederverwendbaren Datenquellen können Sie ein einheitliches Datenmodell für Ihre Organisation erstellen und freigeben. Nur Nutzer, für die Sie die wiederverwendbare Datenquelle freigeben, können sie bearbeiten. Nur der Inhaber der Anmeldedaten für die Datenquelle kann die Verbindungseinstellung ändern.
Weitere Informationen zu Datenquellen
Sie sind neu bei Looker Studio?
Über den Eigenschaftenbereich lassen sich die Daten und der Stil der Tabelle ändern. Über die Symbolleiste können Sie Ihrem Bericht weitere Diagramme, Steuerelemente und andere Komponenten hinzufügen.
Looker Studio kennenlernen
Mit einer BigQuery-Tabelle oder ‑Datenansicht verbinden
Eine BigQuery-Tabelle enthält einzelne Datensätze, die in Zeilen angeordnet sind. Jeder Datensatz besteht aus Spalten (auch Felder genannt). Eine BigQuery-Datenansicht ist eine virtuelle Tabelle, die durch eine SQL-Abfrage definiert wird, die in der BigQuery-Konsole ausgeführt wird.
Wenn Sie eine Verbindung zu einer Tabelle oder Datenansicht herstellen möchten, ist Folgendes erforderlich:
- ein BigQuery-Projekt
- Ein Dataset
- Tabelle oder Ansicht
Projekt
Projekte ermöglichen es Ihnen, Ihre BigQuery-Ressourcen zu organisieren. Sie liefern die erforderlichen Informationen für die Abrechnung, wenn Ihre Berichte die kostenlosen BigQuery-Kontingente überschreiten. Für Abrechnung und Datenverwaltung kann dasselbe Projekt verwendet werden. Sie haben aber auch die Möglichkeit, separate Projekte dafür zu nutzen. Weitere Informationen zu Google Cloud-Projekten
Wählen Sie eine der folgenden Optionen aus, um Ihr Projekt festzulegen:
- LETZTE PROJEKTE
- MEINE PROJEKTE
- FREIGEGEBENE PROJEKTE
Letzte Projekte
Unter LETZTE PROJEKTE sehen Sie die Projekte, auf die Sie in letzter Zeit in der Google Cloud Console zugegriffen haben. Sie können auch die Projekt-ID manuell eingeben. Das ausgewählte Projekt wird sowohl für die Abrechnung als auch für den Datenzugriff verwendet. Wählen Sie nach dem Projekt ein Dataset aus.
Meine Projekte
Über MEINE PROJEKTE können Sie ein beliebiges Projekt auswählen, auf das Sie Zugriff haben. Sie können auch die Projekt-ID manuell eingeben. Das ausgewählte Projekt wird sowohl für die Abrechnung als auch für den Datenzugriff verwendet. Wählen Sie nach dem Projekt ein Dataset aus.
Falls Sie Zugriff auf viele Projekte haben, werden möglicherweise nicht alle in der Liste angezeigt. Wird die maximale Anzahl von Einträgen in der Liste überschritten und das gewünschte Projekt nicht aufgeführt, können Sie es direkt über das Eingabefeld suchen.
Freigegebene Projekte
Über FREIGEGEBENE PROJEKTE können Sie auf ein Projekt zugreifen, das für Sie freigegeben wurde. Sie können unterschiedliche Projekte für Daten und Abrechnung auswählen.
Datasets
Mit Datasets können Sie den Zugriff auf Ihre Daten organisieren und steuern. Wählen Sie das gewünschte Dataset aus der Liste aus oder geben Sie seinen Namen in die Suche ein.
Öffentliche Datasets
Öffentliche BigQuery-Datasets sind öffentliche Beispiele, bei denen zwar das Dataset freigegeben ist, aber nicht das Projekt. Wenn Sie diese Daten abfragen möchten, müssen Sie Ihr eigenes Abrechnungsprojekt angeben. Es wird dann zur Abrechnung der Verarbeitungskosten für die freigegebenen Daten verwendet.
Tabelle
Looker Studio-Datenquellen können mit einer einzelnen Tabelle oder Datenansicht verbunden werden.
Verbindung zu einer nach Datum partitionierten Tabelle herstellen
In Looker Studio können nach Datum partitionierte BigQuery-Tabellen verwendet werden. Wenn Sie eine Verbindung zu einer Tabelle herstellen, die nach einem DATE-, DATETIME- oder TIMESTAMP-Feld partitioniert ist, kann dieses Feld in Looker Studio als Dimension für den Zeitraum für Diagramme verwendet werden, die auf dieser Datenquelle basieren. Wenn Sie diese Option aktivieren möchten, klicken Sie auf der Seite für die Verbindung zur Datenquelle in der Spalte Konfiguration auf das Kästchen Feldname als Zeitraumdimension verwenden.
Wenn für die partitionierte Tabelle in BigQuery ein Partitionsfilter erforderlich ist, ist das Kästchen Feldname als Zeitraumdimension verwenden standardmäßig aktiviert und kann nicht deaktiviert werden.
Weitere Informationen zu nach Datum partitionierten Tabellen in BigQuery
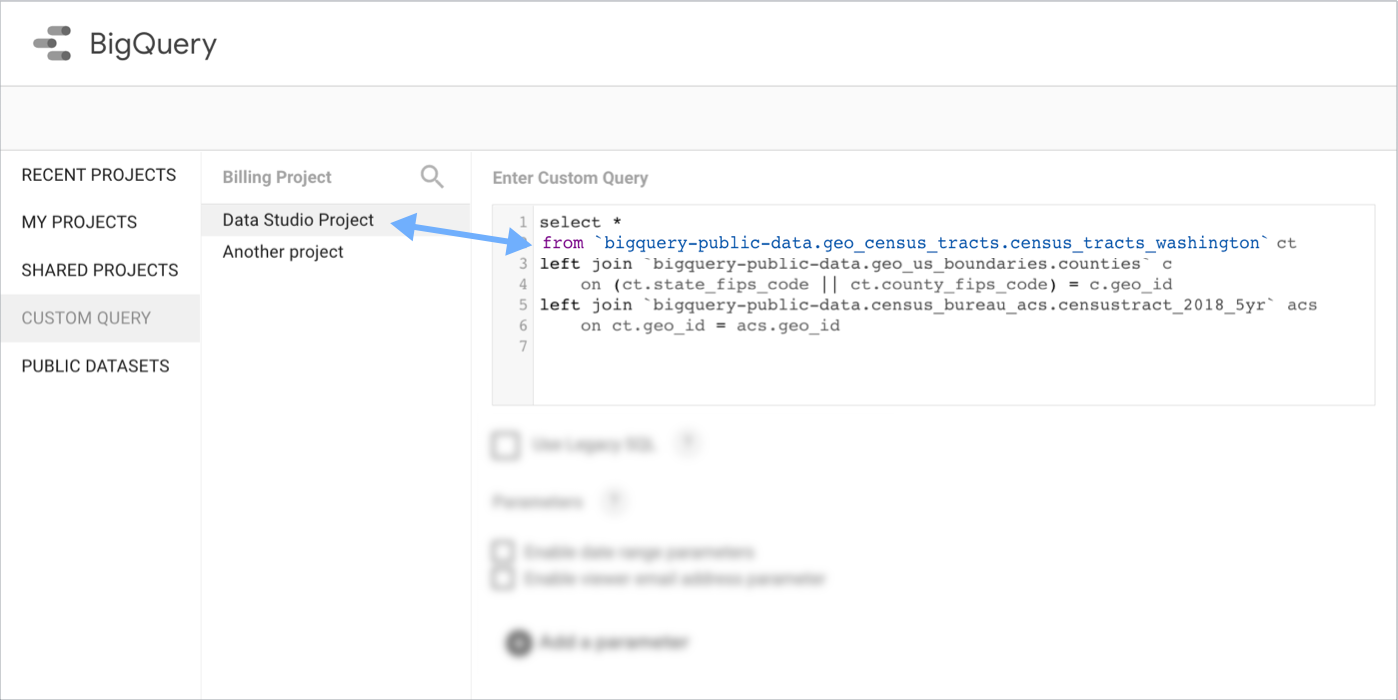
Mit einer benutzerdefinierten SQL-Abfrage eine Verbindung zu BigQuery herstellen
Über BENUTZERDEFINIERTE ABFRAGE können Sie eine SQL-Abfrage schreiben, um eine Verbindung zu Ihren Daten herzustellen. Die Syntax benutzerdefinierter Abfragen entspricht dem SQL-Standarddialekt. Wenn Sie den Legacy-BigQuery-SQL-Dialekt verwenden möchten, wählen Sie die Option Legacy-SQL verwenden aus.
Verwenden Sie die BigQuery-Benutzeroberfläche, um die Abfrage zu verfassen und zu testen. Kopieren Sie sie dann und fügen Sie sie in das Looker Studio-Feld für benutzerdefinierte Abfragen ein.
Abrechnungsprojekt
Über Abrechnungsprojekt können Sie ein Abrechnungsprojekt für Ihre benutzerdefinierte Abfrage angeben, indem Sie nach der Projekt-ID suchen oder sie manuell eingeben. Falls Ihre Organisation viele BigQuery-Projekte hat, müssen Sie das Projekt möglicherweise manuell suchen.
Wenn Sie ein Projekt für die Abrechnung und ein anderes Projekt für Ihre Daten verwenden möchten, wählen Sie das Abrechnungsprojekt in der Benutzeroberfläche aus oder geben Sie es ein. Fügen Sie das Datenprojekt dann in die Klausel SELECT...FROM der benutzerdefinierten Abfrage ein.
Abfrageparameter
Mit Parametern lassen sich flexiblere, anpassbare Berichte erstellen. Sie können Parameter in einer BigQuery-Datenquelle zurück an die zugrunde liegende Abfrage übergeben. Wenn Sie einen Parameter in einer benutzerdefinierten Abfrage verwenden möchten, folgen Sie den Syntaxrichtlinien unter Parametrisierte Abfragen ausführen in BigQuery.
Weitere Informationen zum Verwenden von Parametern in benutzerdefinierten Abfragen
Einschränkungen von benutzerdefinierten Abfragen
Ihre benutzerdefinierte SQL-Abfrage wird als „innere“ SELECT-Anweisung für die jeweilige generierte Datenbankabfrage verwendet. Mit Ihrer benutzerdefinierten Abfrage wird eine neue virtuelle Tabelle generiert, die dann in Looker Studio mit einer eigenen generierten „äußeren“ SQL-Abfrage abgefragt wird. Deshalb unterliegen benutzerdefinierte Abfragen in Looker Studio einigen Einschränkungen:
Benutzerdefinierte SQL-Abfragen dürfen nicht mehr als eine Anweisung enthalten.
Die folgende Abfrage würde z. B. nicht funktionieren, weil sie mehrere SQL-Anweisungen enthält:
DECLARE cost_per_tb_in_dollar FLOAT64 DEFAULT 4.2;
SELECT total_bytes_billed / (1024 * 1024)* cost_per_tb_in_dollar)/(1024*1024))) FROM billing-table;
In Joins müssen eindeutige Feldnamen enthalten sein.
In benutzerdefinierten Join-Abfragen sind keine doppelten Spaltennamen zulässig. Für Diagramme, die eine Datenquelle verwenden, die auf einer benutzerdefinierten Abfrage mit doppelten Feldern basiert, wird ein Nutzerkonfigurationsfehler ähnlich dem folgenden zurückgegeben:
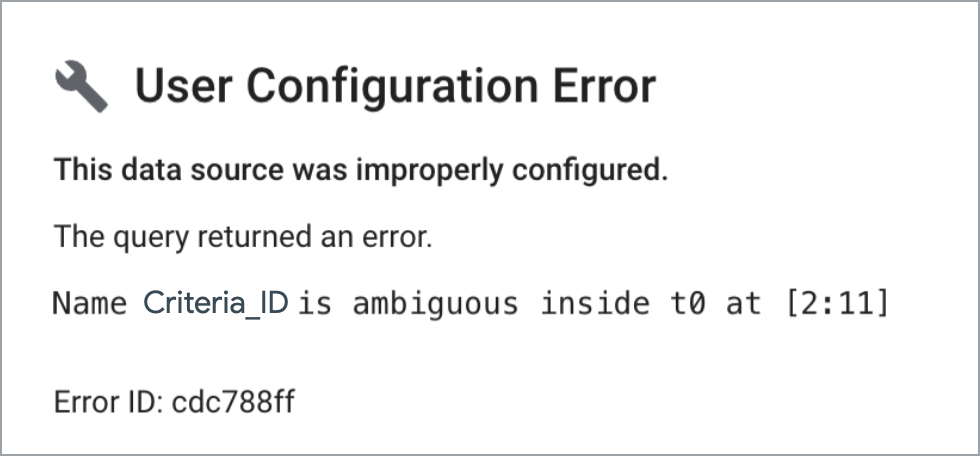
Dieses Problem tritt nicht auf, wenn Sie in Ihren benutzerdefinierten Abfragen immer eindeutige Feldnamen verwenden.
Angenommen, Sie kombinieren mit Join zwei Tabellen mit identischen Schemas und verwenden dazu das Feld Criteria_ID, das in beiden Tabellen vorhanden ist.
SELECT * FROM (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_1'
) As table_1
LEFT JOIN (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_2'
) As table_2
ON
table_1.Criteria_ID = table_2.Criteria_ID
Diese Abfrage enthält die folgenden doppelten Spaltennamen:
Criteria_IDParent_IDName
Sie können den Fehler Field is ambiguous vermeiden, indem Sie die doppelten Felder mit dem Schlüsselwort AS explizit umbenennen:
SELECT *
FROM (
SELECT
Criteria_ID AS Criteria_ID_1,
Parent_ID AS Parent_ID_1,
Name AS NAME_1
FROM
'table_1' ) AS table_1
LEFT JOIN (
SELECT
Criteria_ID AS Criteria_ID_2,
Parent_ID AS Parent_ID_2,
Name AS NAME_2
FROM
'table_2' ) AS table_2
ON
table_1.Criteria_ID_1 = table_2.Criteria_ID_2;
Wenn Sie nur wenige Felder umbenennen müssen, können Sie in die SELECT-Anweisung alle Felder mit Ausnahme (EXCEPT) der Felder aufnehmen, die Sie umbenennen möchten. Beispiel:
SELECT * EXCEPT (city), city AS city_1 FROM 'table_1'
Zeitüberschreitung bei Abfragen
Bei benutzerdefinierten Abfragen in Looker Studio kann es nach drei bis fünf Minuten zu einer Zeitüberschreitung kommen. So können Sie diesem Problem entgegenwirken:
- Vereinfachen Sie die Abfrage, damit sie schneller ausgeführt werden kann.
- Führen Sie die Abfrage in Ihrer Datenbank aus und speichern Sie die Ergebnisse in einer separaten Tabelle. Stellen Sie dann eine Verbindung zwischen der Tabelle und Ihrer Datenquelle her.
Mehrtägige Tabellen
In BigQuery sind Abfragen für mehrere Tabellen möglich, bei denen jede Tabelle die Daten eines Tages enthält. Die Tabellen haben das Format YYYYMMDD. Tabellen mit diesem Format werden in Looker Studio als mehrtägige Tabellen gekennzeichnet. Außerdem wird in der Tabellenauswahl nur der Name „Präfix_JJJJMMTT“ angezeigt.YYYYMMDD
Wenn ein Diagramm erstellt wird, um diese Tabelle grafisch darzustellen, wird in Looker Studio automatisch ein Standardzeitraum festgelegt, der die letzten 28 Tage umfasst. Daher werden die Daten der letzten 28 Tabellen abgerufen. Sie können diese Einstellung ändern, indem Sie den Bericht bearbeiten, das Diagramm auswählen und dann auf dem Tab DATEN den Zeitraum anpassen.
An BigQuery gesendete SQL-Abfragen ansehen
Sie können sich alle BigQuery-SQL-Abfragen ansehen, die in Looker Studio generiert werden. Dazu rufen Sie einfach den entsprechenden Bereich der BigQuery-Benutzeroberfläche auf.
Messwert „Datensatzanzahl“
Für BigQuery-Datenquellen wird automatisch der standardmäßige Messwert Datensatzanzahl bereitgestellt. Damit können Sie Ihre Dimensionen aufschlüsseln, um sich die Anzahl der Datensätze anzeigen zu lassen, die in Ihren Diagrammen aggregiert wurden.
Unterstützung von VPC Service Controls
Looker Studio kann über IP-basierte Zugriffsebenen für Betrachter eine Verbindung zu BigQuery-Projekten herstellen, die durch VPC Service Control-Perimeter (VPC-SC) geschützt sind. Über den BigQuery-Connector wird die IP-Adresse des Betrachters an BigQuery übergeben. Dadurch kann eine der eingerichteten IP-basierten Zugriffsebenen erzwungen werden.
BigQuery-GEOGRAPHY-Polygone visualisieren
In Ihrem Bericht können Sie GEOGRAPHY-Polygone mithilfe einer Google Maps-Visualisierung anzeigen lassen. Eine Anleitung finden Sie unter GEOGRAPHY-Polygone aus BigQuery in Looker Studio visualisieren.
Looker Studio-Abfragen anhand von Joblabels analysieren
Alle Abfragen, die von Looker Studio an BigQuery gesendet werden, werden mit dem BigQuery-Joblabel requestor:looker_studio versehen. Sie können dieses Joblabel verwenden, um BigQuery-Abfragen mit Bezug zu Looker Studio zu identifizieren. Weitere Informationen zu Labels in BigQuery finden Sie auf der BigQuery-Dokumentationsseite Labels ansehen.
Weitere Informationen zum Überwachen der Leistung und Kosten von Looker Studio-Diagrammen und ‑Berichten finden Sie auf der BigQuery-Dokumentationsseite Daten mit Looker Studio analysieren.
BigQuery-Dialogfeld
Wenn Sie Inhaber-Anmeldedaten für die BigQuery-Datenquelle haben, wird in Looker Studio in jedem Diagramm, in dem BigQuery verwendet wird, rechts oben ein BigQuery-Symbol angezeigt. Bewegen Sie den Mauszeiger auf das Diagramm und klicken Sie dann auf das BigQuery-Symbol, um das Dialogfeld BigQuery zu öffnen. Im Dialogfeld wird ein Link zur Seite mit den BigQuery-Jobdetails angezeigt. Auf der Seite mit den BigQuery-Jobdetails finden Sie die folgenden Informationen:
- Die SQL-Abfrage für das Diagramm
- Die Daten, die von der SQL-Abfrage zurückgegeben wurden
- Aufschlüsselung der Abfrageschritte nach Phase
- Abfragestatistiken wie Gesamtlaufzeit und verwendete Slots
Kontingente und allgemeine Limits
Mit dem BigQuery-Connector können maximal 2 Millionen Zeilen zurückgegeben werden. In Looker Studio wird angezeigt, wenn es mehr Datenzeilen gibt. Die Anzahl der Zeilen wird jedoch nicht angegeben.
Darüber hinaus unterliegen BigQuery-Datenquellen denselben Raten- und Kontingentlimits wie BigQuery selbst.
Bei BigQuery-Datenquellen wird MEDIAN mithilfe der BigQuery-Funktion APPROX_QUANTILES implementiert. Die Anwendung von MEDIAN auf Daten aus BigQuery kann zu geringfügig anderen Ergebnissen führen als die Anwendung von MEDIAN auf dieselben Daten aus anderen Datenquellen.