BigQuery is Google's fully managed, petabyte scale, low-cost analytics data warehouse. The Looker Studio BigQuery connector lets you access data from your BigQuery tables within Looker Studio.
Before you begin
To access BigQuery data in Looker Studio, you'll need to provide a Google Cloud Billing account. BigQuery is a paid product, and you may incur BigQuery usage costs when you access BigQuery through Looker Studio. Learn more about BigQuery pricing.
How to connect to BigQuery
You can connect Looker Studio to a table, a view, or a custom query in Google BigQuery.
Steps to connect
Click Create and then select Report.
The report editor appears, and the Add data to report panel opens.
To create a new embedded data source, select the BigQuery connector.
- To select an existing reusable data source, click the My data sources tab, and then select a data source of any type that you've created previously or that has been shared with you.
Configure the data source connection to your BigQuery data. You can connect to a BigQuery table or view, or you can connect using a custom SQL query.
Click Add.
In a moment, a table that is connected to the data source appears on the report canvas.
Embedded versus reusable data sources explained
Data sources can be either embedded or reusable. Reports can include both embedded and reusable data sources.
Data sources that you create while editing a report are embedded in the report. To edit an embedded data source, you do so within that report. Embedded data sources make collaborating on reports and data sources easier. Anyone who can edit the report can also edit the data source as well as modify its connection. When you share or copy the report, any embedded data sources are shared or copied as well.
Data sources that you create from the home page are reusable. You can reuse these data sources in different reports. Reusable data sources let you create and share a consistent data model across your organization. Only people with whom you share the reusable data source can edit it. Only the owner of the data sources credentials can modify the connection.
Learn more about data sources.
New to Looker Studio?
Use the properties panel to change the data and style of the table. Use the toolbar to add more charts, controls, and other components to your report.
Get to know Looker Studio
Connect to a BigQuery table or view
A BigQuery table contains individual records organized in rows. Each record is composed of columns (also called fields ). A BigQuery view is a virtual table that is defined by a SQL query that is executed in the BigQuery console.
To connect to a table or view, you'll need to supply the following information:
- A BigQuery project
- A dataset
- A table or view
Project
Projects organize your BigQuery resources and provide the required information for billing if your reports exceed BigQuery's free quotas. You can use the same project for both billing and data management, or you can use one project for the data while billing another project. Learn more about Google Cloud Projects.
Choose one of the following options to select your project:
- RECENT PROJECTS
- MY PROJECTS
- SHARED PROJECTS
Recent projects
The RECENT PROJECTS option shows you the projects that you've accessed recently in the Google Cloud console. You can also enter the project ID manually. The project that you choose is used both for billing and for data access. After selecting a project, you'll select a dataset.
My projects
The MY PROJECTS option lets you select any project to which you have access. You can also enter the project ID manually. The project that you choose is used both for billing and for data access. After selecting a project, you'll select a dataset.
If you have access to many projects, it's possible that they may not all appear in the list. When the list exceeds the maximum number of items, you can enter the unlisted project directly by typing it in the entry field.
Shared projects
The SHARED PROJECTS option lets you access a project that's been shared with you. You can select different projects for data and billing.
Datasets
Datasets are used to organize and control access to your data. Select a dataset from the list, or search for a dataset by name.
Public datasets
BigQuery public datasets are public samples, where the dataset is shared but the project is not. To query this data, you must specify your own billing project, which will be used to bill for processing costs on the shared data.
Table
You can connect a Looker Studio data source to a single table or view.
Connect to a date-partitioned table
Looker Studio can take advantage of BigQuery date partitioned tables. When you connect to a table that is partitioned on a DATE, DATETIME, or TIMESTAMP field, Looker Studio can use that field as the date range dimension for charts that are based on this data source. To enable this option, check the Use fieldname as date range dimension checkbox that appears in the Configuration column of the data source connection page.
If the partitioned table in BigQuery requires a partition filter, the Use fieldname as date range dimension checkbox is selected by default and can't be cleared.
Learn more about date-partitioned tables in BigQuery.
Connect to BigQuery using a custom SQL query
The CUSTOM QUERY option lets you connect to your data by writing SQL. The custom query syntax follows the Standard SQL dialect. To use the legacy BigQuery SQL dialect, select the Use Legacy SQL option.
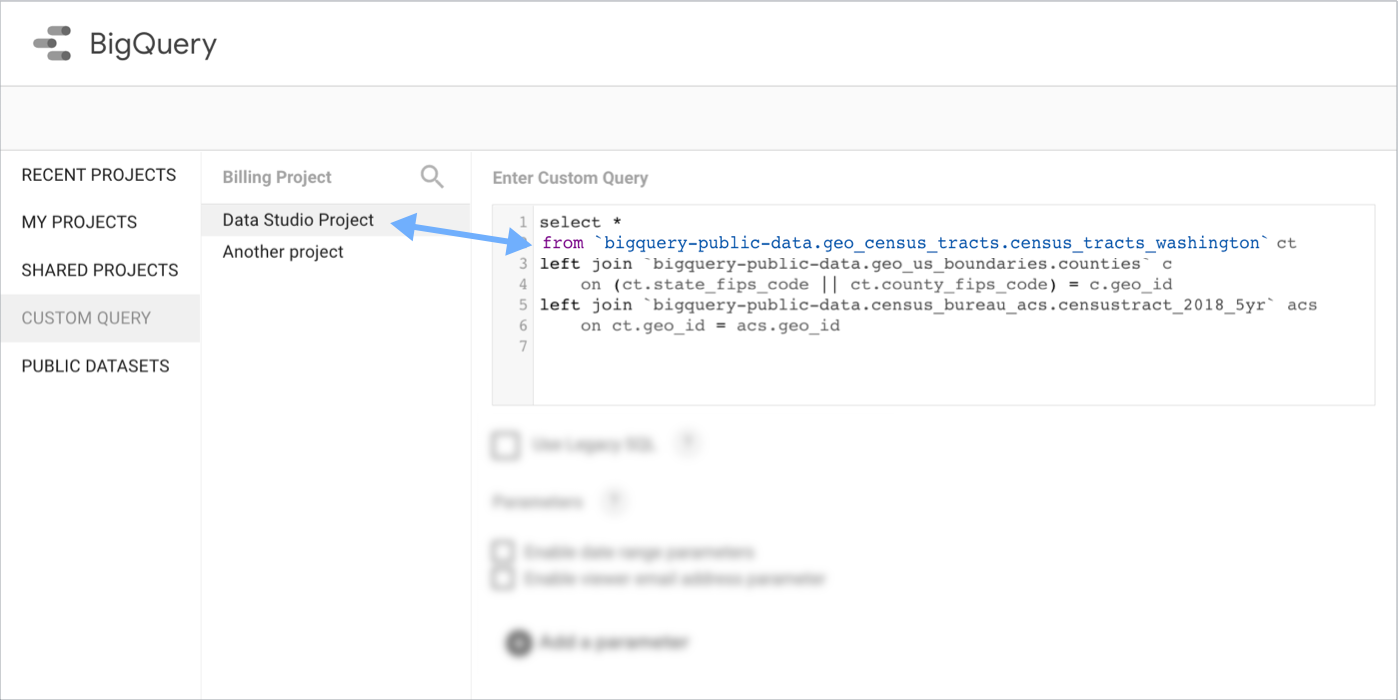
Use the BigQuery user interface to compose and test your query, and then copy and paste that query into the Looker Studio custom query box.
Billing project
The Billing Project option lets you supply a billing project for your custom query by either searching for or entering the project ID manually. If your organizations has many BigQuery projects, you may need to use the manual entry method to locate the project.
To use one project for billing and a different project for your data, select or enter the billing project in the user interface, and then include the data project in the SELECT...FROM clause of the custom query.
Query parameters
Parameters let you build more responsive, customizable reports. You can pass parameters in a BigQuery data source back to the underlying query. To use a parameter in your custom query, follow the syntax guidelines for running parameterized queries in BigQuery.
Learn more about using parameters in custom queries.
Limits of custom queries
Looker Studio uses your custom SQL as an inner SELECT statement for each generated query to the database. In effect, your custom query generates a new, virtual table, which Looker Studio then queries with its own generated "outer" SQL. Because of this, custom queries in Looker Studio are subject to a few restrictions:
Custom SQL queries may only have a single statement
For example, the following won't work because it has multiple SQL statements:
DECLARE cost_per_tb_in_dollar FLOAT64 DEFAULT 4.2;
SELECT total_bytes_billed / (1024 * 1024)* cost_per_tb_in_dollar)/(1024*1024))) FROM billing-table;
Use unambiguous field names in joins
Custom join queries can't handle duplicate column names. Charts using a data source that is based on a custom query that includes duplicate fields will return a user configuration error similar to the following:
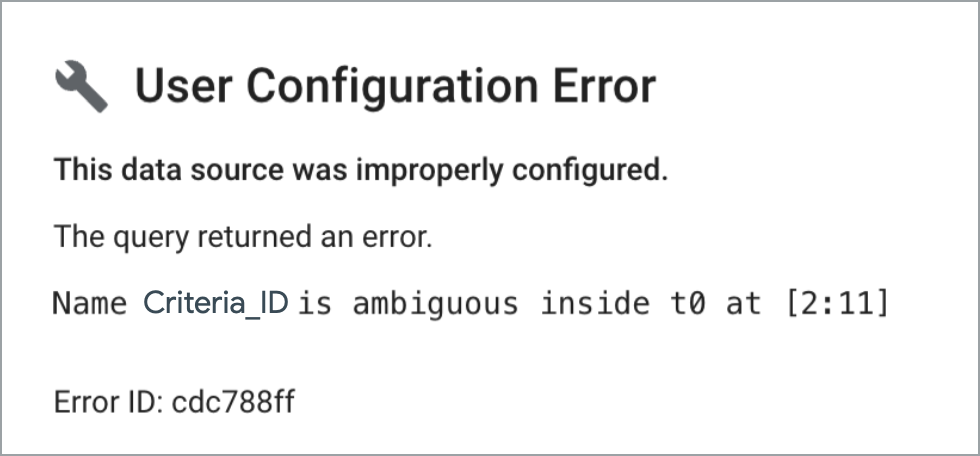
To avoid this issue, be sure to use unambiguous field names in your custom queries.
For example, say you are joining two tables with identical schemas, joining on a Criteria_ID field found in both tables.
SELECT * FROM (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_1'
) As table_1
LEFT JOIN (
SELECT Criteria_ID, Parent_ID, Name FROM 'table_2'
) As table_2
ON
table_1.Criteria_ID = table_2.Criteria_ID
This query includes the following duplicate column names:
Criteria_IDParent_IDName
To avoid the Field is ambiguous error, you can explicitly rename the duplicated fields using the AS keyword:
SELECT *
FROM (
SELECT
Criteria_ID AS Criteria_ID_1,
Parent_ID AS Parent_ID_1,
Name AS NAME_1
FROM
'table_1' ) AS table_1
LEFT JOIN (
SELECT
Criteria_ID AS Criteria_ID_2,
Parent_ID AS Parent_ID_2,
Name AS NAME_2
FROM
'table_2' ) AS table_2
ON
table_1.Criteria_ID_1 = table_2.Criteria_ID_2;
If you need to rename only a few fields, you can select everything except the ones that you want to rename, for example:
SELECT * EXCEPT (city), city AS city_1 FROM 'table_1'
Query timeout
Custom queries in Looker Studio may time out after three to five minutes. If your custom queries time out, try the following approaches to resolve the issue:
- Simplify the query so that it runs faster.
- Run the query in your database and store the results in a separate table. Then connect to that table in your data source.
Multi-day tables
BigQuery supports querying across multiple tables, where each table has a single day of data. The tables have the format of YYYYMMDD. When Looker Studio encounters a table that has the format of YYYYMMDD, the table will be marked as a multi-day table, and only the name prefix_YYYYMMDD will be displayed in the table select.
When a chart is created to visualize this table, Looker Studio will automatically create a default date range of the last 28 days and then properly query the last 28 tables. You can configure this setting by editing the report, selecting the chart, and then adjusting the Date Range properties in the chart's DATA tab.
View SQL issued to BigQuery
You can view all the BigQuery SQL that Looker Studio has generated from within the BigQuery Query History user interface.
Record Count metric
BigQuery data sources automatically provide a default Record Count metric. You can use this to break down your dimensions to show the number of records that are being aggregated by your charts.
Support for VPC Service Controls
Looker Studio can connect to BigQuery projects that are protected by VPC Service Controls (VPC-SC) perimeters through viewer IP-based access levels. The BigQuery connector passes the report viewer's IP address to BigQuery, which can then enforce any IP-based access levels that have been set up.
Visualize BigQuery GEOGRAPHY polygons
You can display GEOGRAPHY polygons by using a Google Maps visualization in your report. See Visualize BigQuery GEOGRAPHY polygons with Looker Studio for a tutorial.
Analyze Looker Studio queries with job labels
All queries that are sent by Looker Studio to BigQuery have the BigQuery job label requestor:looker_studio. You can use this job label to identify BigQuery queries that are related to Looker Studio. For more information about labels in BigQuery, see the Viewing labels BigQuery documentation page.
For more information about tracking the performance and cost of Looker Studio charts and reports, see the Analyze data with Looker Studio BigQuery documentation page.
BigQuery dialog
If you have owner credentials on the BigQuery data source, Looker Studio will display a BigQuery icon in the upper right corner of any chart that uses BigQuery. Hover over the chart, and then click the BigQuery icon to open the BigQuery dialog. The dialog displays a link to the BigQuery job details page. The BigQuery job details page includes the following information:
- The SQL query for the chart
- The data that the SQL query returned
- A per-stage breakdown of the query steps
- Query statistics such as total runtime and slots used
Quotas and general limits
The maximum number of rows that can be returned using the BigQuery Connector is 2 million rows. Looker Studio will indicate when there are over 2 million rows of data, but it won't specify the number of rows.
In addition, BigQuery data sources are subject to the same rate limits and quota limits as BigQuery itself.
For BigQuery data sources, MEDIAN is implemented using the BigQuery APPROX_QUANTILES function. Applying MEDIAN to data coming from BigQuery may return slightly different results than applying MEDIAN to the same data coming from other data source types.