| Ta funkcja jest dostępna tylko w Google Analytics 360, części Google Marketing Platform. Więcej informacji o Google Marketing Platform |
Metodologia atrybucji opartej na danych dzieli się na dwa główne etapy: (1) analiza wszystkich dostępnych danych o ścieżkach w celu opracowania niestandardowych modeli prawdopodobieństwa wystąpienia konwersji oraz (2) zastosowanie do tego zbioru prawdopodobnych danych zaawansowanego algorytmu, który przypisze częściowe statystyki konwersji do Twoich punktów stykowych marketingu.
Opracowywanie modeli prawdopodobieństwa wystąpienia konwersji na podstawie wszystkich dostępnych danych o ścieżkach
Atrybucja oparta na danych wykorzystuje wszystkie dostępne dane o ścieżkach, w tym dane pochodzące zarówno od użytkowników dokonujących konwersji, jak i użytkowników niedokonujących konwersji. Służy to ocenie, jak występowanie określonych punktów stykowych marketingu wpływa na prawdopodobieństwo dokonania konwersji przez użytkowników. Otrzymane modele prawdopodobieństwa pokazują, jak prawdopodobne jest, że użytkownik dokona konwersji w określonym punkcie ścieżki przy uwzględnieniu konkretnej sekwencji zdarzeń.
Algorytmiczne przypisywanie statystyk konwersji do punktów stykowych marketingu
Następnie atrybucja oparta na danych stosuje to tego zbioru prawdopodobnych danych algorytm oparty na pojęciu wartości Shapley'a znanym z teorii gier koalicyjnych. Wartość Shapley'a została opracowana przez Lloyda S. Shapley'a, laureata Nagrody Nobla w dziedzinie ekonomii, i jest to sposób sprawiedliwego podziału wypłaty danego zespołu wśród jego członków.
W przypadku atrybucji opartej na danych „członkami” analizowanego „zespołu” są punkty stykowe marketingu (np. bezpłatne wyniki wyszukiwania, sieć reklamowa oraz poczta e-mail), a jego „wypłatą” są konwersje. Algorytm atrybucji opartej na danych oblicza kontrfaktyczne korzyści każdego punktu stykowego marketingu, czyli porównuje prawdopodobieństwo dokonania konwersji przez podobnych użytkowników, którzy zetknęli się z tymi punktami stykowymi, z prawdopodobieństwem wystąpienia konwersji w sytuacji, gdyby jednego z tych punktów stykowych zabrakło na ścieżce.
Rzeczywiste obliczenie statystyk konwersji dla każdego punktu stykowego zależy od porównania wszystkich kombinacji punktów stykowych i ujednolicenia ich. To oznacza, że algorytm atrybucji opartej na danych bierze pod uwagę kolejność występowania poszczególnych punktów stykowych i przypisuje różne statystyki dla różnych pozycji na ścieżce. Jeśli na przykład sieć reklamowa poprzedza płatne wyszukiwanie, model jest inny niż wtedy, gdy płatne wyszukiwanie poprzedza sieć reklamową.
Przykład
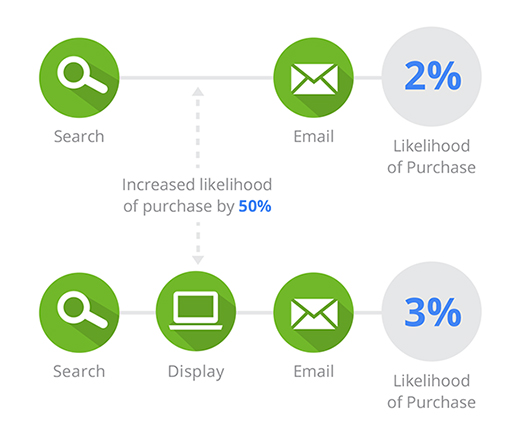
W poniższym ogólnym przykładzie kombinacja bezpłatnych wyników wyszukiwania, sieci reklamowej oraz poczty e-mail daje 3% prawdopodobieństwo wystąpienia konwersji. Gdy sieć reklamowa zostanie usunięta, prawdopodobieństwo spadnie do 2%. Zaobserwowany wzrost o 50% przy obecności sieci reklamowej jest podstawą do przypisania udziału w konwersji.
Poznanie modelu opartego na danych i analiza jego wpływu na ROI
Raport Eksplorator modeli umożliwia poznanie konkretnych wag ustawionych przez model oparty na danych na podstawie kanału i pozycji. (Aby uzyskać bardziej szczegółową analizę, możesz pobrać model jako plik CSV). Do porównania modeli i zidentyfikowania możliwości optymalizacji użyj Narzędzia porównywania modeli. Raport Analiza ROI umożliwia poznanie wpływu modelu opartego na danych na ROI.
