| Denne funktion er kun tilgængelig i Google Analytics 360, som er en del af Google Marketing Platform. Få flere oplysninger om Google Marketing Platform. |
Der er to hovedpunkter i forbindelse med metodikken for datadrevet tilskrivning: (1) analyse af alle de tilgængelige stidata for at udvikle tilpassede modeller for konverteringssandsynlighed samt (2) anvendelse af dette datasæt for sandsynlighed i en avanceret algoritme, der tildeler marketingberøringspunkterne delvis konverteringskredit.
Udvikling af modeller for konverteringssandsynlighed ud fra alle tilgængelige stidata
Datadrevet tilskrivning bruger alle tilgængelige stidata – inklusive data fra både konverterende og ikke-konverterende brugere – for at forstå, hvordan tilstedeværelsen af bestemte marketingberøringspunkter påvirker dine brugeres sandsynlighed for konvertering. De fremkomne sandsynlighedsmodeller viser, hvor sandsynligt det er, at en bruger konverterer på et givet punkt i stien i løbet af en bestemt sekvens af hændelser.
Algoritmisk tildeling af konverteringskredit til marketingberøringspunkter
Datadrevet tilskrivning anvender derefter dette sandsynlighedsmæssige datasæt i en algoritme baseret på et koncept fra kooperativ spilteori, som kaldes Shapley-værdi. Shapley-værdien er udviklet af Nobelprismodtageren i økonomi Lloyd S. Shapley og er en tilgang til fair fordeling af et teams output blandt teamets medlemmer.
I forbindelse med datadrevet tilskrivning har det "team", der analyseres, marketingberøringspunkter (f.eks. Organisk søgning, Display og E-mail) som “teammedlemmer”, og teamets “output” er konverteringer. Algoritmen for datadrevet tilskrivning beregner kontrafaktiske stigninger for hvert marketingberøringspunkt – dvs. den sammenligner konverteringssandsynligheden for lignende brugere, der blev eksponeret for disse berøringspunkter, med sandsynligheden, når et af berøringspunkterne ikke findes i stien.
Den faktiske beregning af konverteringskredit for hvert enkelt berøringspunkt afhænger af sammenligningen af alle de forskellige permutationer af berøringspunkter og normalisering på tværs af dem. Det betyder, at algoritmen for datadrevet tilskrivning tager højde for hvert enkelt berøringspunkts plads i rækkefølgen og tildeler forskellig kredit for forskellige stipositioner. F.eks. modelleres Display, som kommer før Betalt søgning, adskilt i forhold til Betalt søgning, som kommer førDisplay.
Eksempel
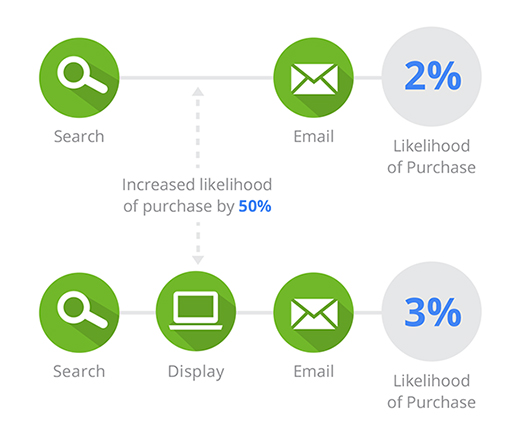
I det følgende højniveau-eksempel fører kombinationen af Organisk søgning, Display og E-mail til en konverteringssandsynlighed på 3 %. Når Display fjernes, falder sandsynligheden til 2 %. Den observerede stigning på 50 %, når Display forefindes, fungerer som basis for tilskrivningen.
Undersøgelse af den datadrevne model, og analyse af dens implikationer for investeringsafkastet
Du kan bruge rapportenModelundersøger til at undersøge de specifikke vægtninger, som den datadrevne model angiver baseret på kanal og position. (Du kan downloade modellen som CSV-fil for at se en mere detaljeret analyse). Brug værktøjet til sammenligning af modeller til at sammenligne modeller og identificere optimeringsmuligheder. Rapporten Analyse af investeringsafkast giver dig indblik i den datadrevne models implikationer for investeringsafkastet.
